


MapReduce是一种编程模型,用于处理和生成大数据集。倒序_MapReduce是其一个变种,主要用于实现数据的逆序处理。在倒序_MapReduce中,Map阶段负责将数据进行逆序处理,而Reduce阶段则负责将处理后的数据进行汇总和输出。
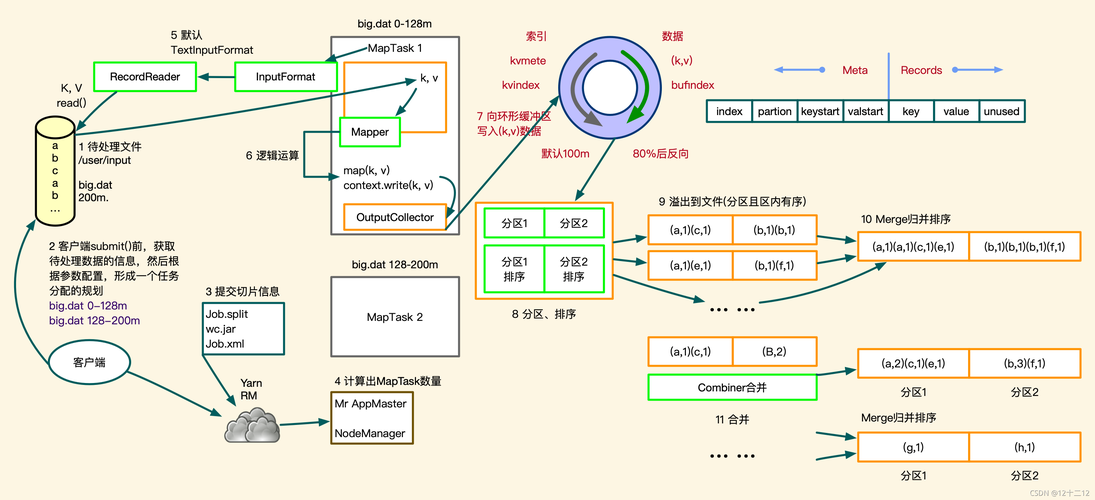
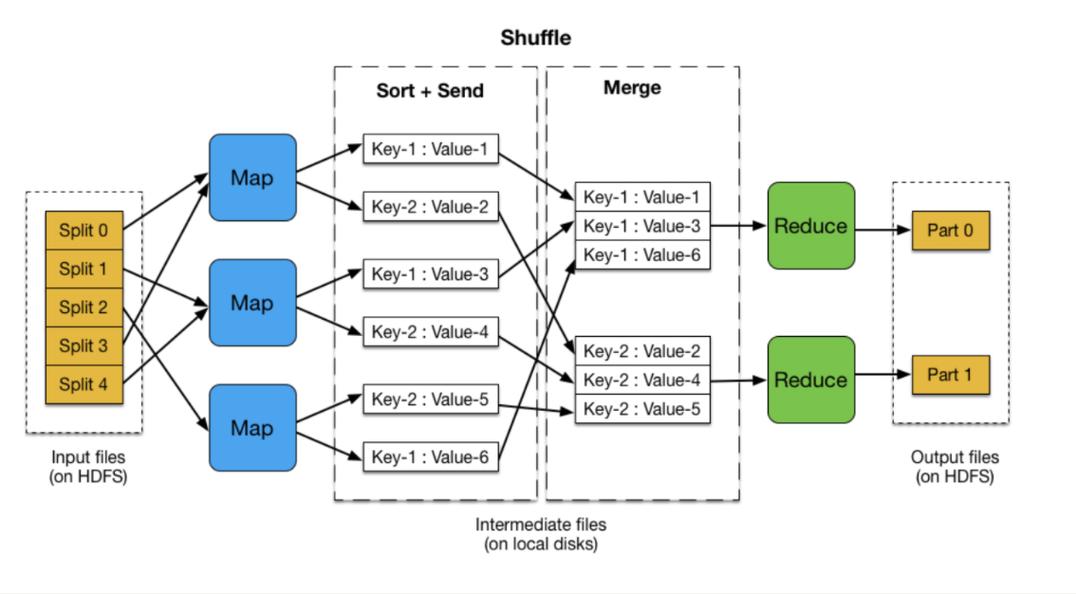
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,倒序_MapReduce指的是在MapReduce过程中对数据进行倒序处理,下面是一个详细的步骤说明:

(图片来源网络,侵删)
1、Mapper阶段:
输入:原始数据集(例如文本文件)
输出:键值对(keyvalue pairs),其中键是每行数据的标识符(例如行号),值是该行的文本内容
2、Shuffle阶段:
功能:将Mapper阶段的输出按照键进行排序和分组
输出:按键排序后的键值对列表
3、Reducer阶段:

(图片来源网络,侵删)
输入:来自Shuffle阶段的已排序键值对列表
输出:处理后的结果,通常是最终的输出数据集
4、倒序处理:
在Mapper阶段,可以将每一行的文本内容与其对应的行号作为键值对输出。
在Reducer阶段,可以按照行号的逆序来处理这些键值对,从而实现倒序处理。
下面是一个简单的Python代码示例,使用Hadoop Streaming API实现倒序_MapReduce:
mapper.py
import sys
for line in sys.stdin:
# 去除行尾的换行符
line = line.strip()
# 输出键值对,键为行号,值为文本内容
print(f"{line}")
reducer.py
import sys
lines = []
for line in sys.stdin:
# 读取所有输入行并存储到列表中
lines.append(line.strip())
按行号逆序排序
lines.sort(reverse=True)
输出排序后的行
for line in lines:
print(line) 要运行这个MapReduce作业,你需要将上述代码保存为mapper.py和reducer.py,然后使用Hadoop Streaming命令执行:
(图片来源网络,侵删)
hadoop jar /path/to/hadoopstreaming.jar n input /path/to/input/data n output /path/to/output/data n mapper mapper.py n reducer reducer.py n file mapper.py n file reducer.py
这样,你就可以得到一个按照行号逆序排列的输出结果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/854276.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复