


在当今大数据时代,对海量数据的处理已成为技术发展的一个重要方向,MapReduce作为处理大规模数据集的编程模型,已被广泛应用于各种实际场景中,本文将深入探讨MapReduce模型在数据分类方面的应用及其具体实现方式,通过具体的实例与操作流程的介绍,我们能够更好地理解MapReduce在数据处理中的重要角色及其实现机制。
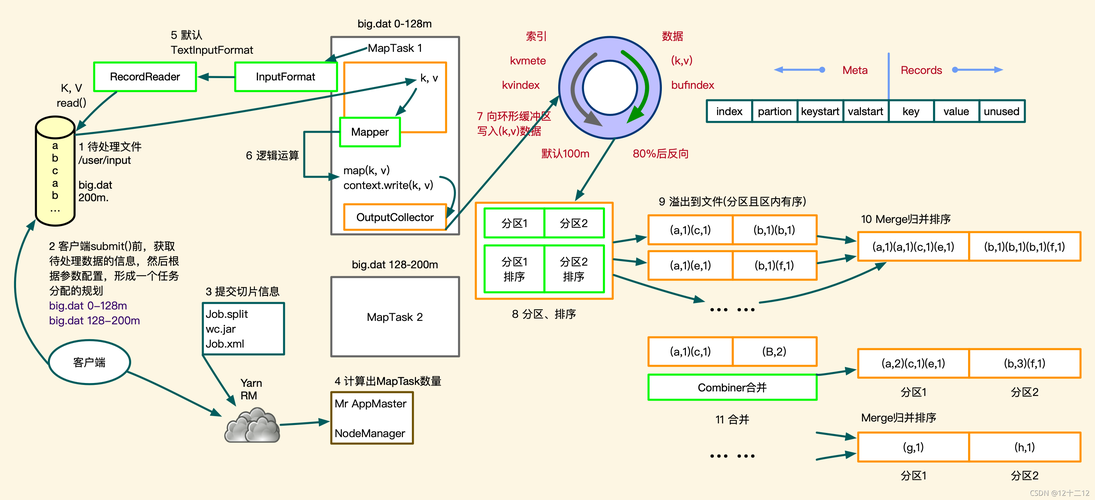

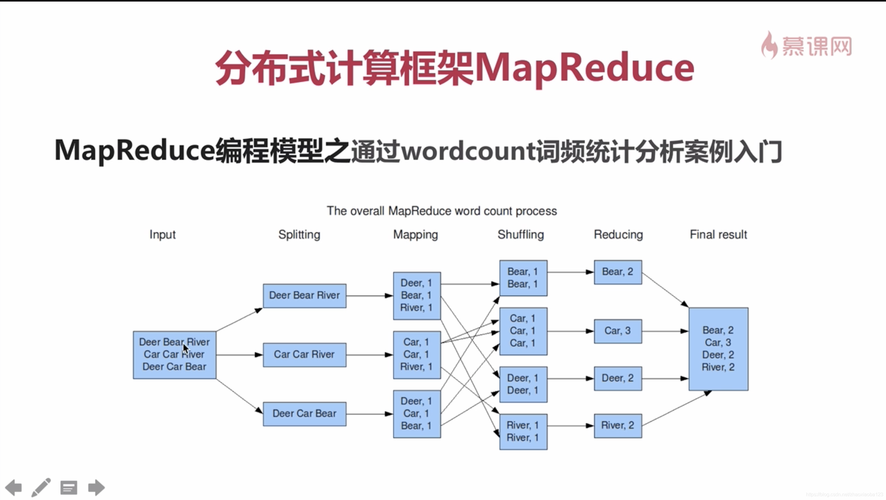
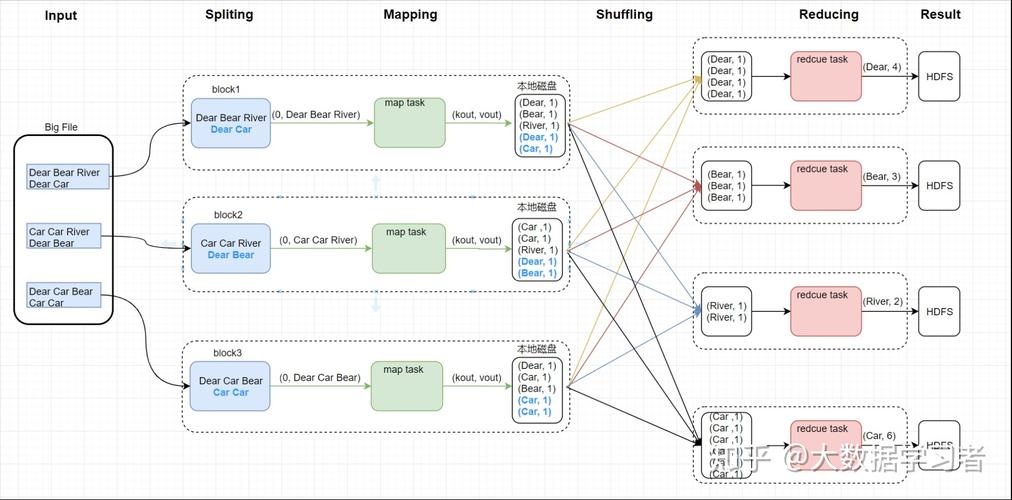
MapReduce的基本概念由Google提出,并最初用于支持其搜索功能中的大量数据处理,MapReduce分为两个主要阶段:Map(映射)和Reduce(归约),在Map阶段,系统将输入数据分割成独立的小块,分布到不同的节点上进行处理;而在Reduce阶段,则将所有Map阶段的结果汇总起来,得到最终结果,这种模型非常适合于大规模的数据并行处理,因为它可以高效地利用分布式系统的资源。
使用MapReduce进行数据分类的一个典型例子是JSON数据的分类存储,在这个过程中,首先需要自定义一个对象来存储数据,如果我们需要按照性别和文理科对数据进行分类,可以通过定义一个包含这些属性的对象来实现,Mapper阶段会读取原始数据,并根据分类要求将数据映射到不同的类别中,这通常涉及到数据的解析和初步处理,例如将JSON字符串转换成预定义的格式,在Reducer阶段,系统会将相同类别的数据聚合在一起,执行更复杂的数据处理,如统计或进一步的筛选,在Driver阶段,我们配置和控制整个MapReduce作业的运行,包括作业的提交、监控和结果的收集。
另一个应用示例是朴素贝叶斯分类器的实现,朴素贝叶斯分类器基于贝叶斯定理,具有算法简单、分类速度快等优点,在MapReduce框架下实现朴素贝叶斯分类器,首先需要准备训练数据集,并计算先验概率和条件概率,在Map阶段,通过对数据集的处理计算出各个特征的频率及类别的概率;而在Reduce阶段,则根据Map阶段的输出整合计算出最终的分类决策,这一过程展示了如何将统计学方法与大数据技术结合,以解决实际问题。
通过以上讨论,可以看出MapReduce在数据分类领域的应用不仅具有理论上的可行性,而且在实际操作中也表现出了高效的处理能力,对于初学者而言,掌握MapReduce的逻辑和编程模式需要一定的学习和实践,为了更好地理解和运用MapReduce进行数据分类,以下是一些建议:
1、深入学习MapReduce的工作原理和架构设计,特别是数据流和控制流的管理。
2、实践使用不同编程语言实现MapReduce程序,比如Java、Python等,以适应不同的平台和需求。
3、探索更多案例和应用场景,如文本分析、日志处理等,以丰富对MapReduce应用的理解。
MapReduce作为一种强大的数据处理工具,在数据分类方面展示了其独特的优势和广泛的应用前景,无论是处理简单的数据归类还是实现复杂的机器学习算法,MapReduce都能提供有效的解决方案,随着技术的不断进步和应用需求的增加,预计未来MapReduce将在数据科学和大数据处理领域发挥更加重要的作用。
FAQs
Q1: MapReduce在数据分类中有哪些限制?
A1: 尽管MapReduce在处理大规模数据集方面非常有效,但它也有一些限制,对于需要实时响应的应用,由于MapReduce作业启动和数据处理的延迟,可能不是最佳选择,对于小量数据的处理,使用MapReduce可能不如传统的单机处理效率高。
Q2: 如何优化MapReduce作业的性能?
A2: 优化MapReduce作业性能可以从多方面入手,例如合理设置数据块大小以平衡负载,选择合适的数据类型和格式以减少处理时间,以及优化算法逻辑减少不必要的计算和数据传输,合理配置硬件资源和调整Hadoop集群的配置参数也能显著提高作业的执行效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/853960.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复