


MapReduce是一种革命性的并行计算模型和方法,它不仅体现了分布式系统的强大能力,还显示了函数式编程的优雅和简洁。

MapReduce的概念最早由Google公司提出,旨在处理其搜索引擎中大规模的网页数据,Google面临的巨大数据处理需求催生了这一模型的发展,并最终促进了其在大规模数据并行处理领域的广泛应用,随后,这一概念被进一步实现和普及,尤其是通过Hadoop这一开源框架,下面将深入探讨MapReduce的核心思想与架构设计:
1、概念起源
灵感来源:MapReduce的灵感来源可追溯至函数式语言(如Lisp)中的内置函数map和reduce,这些函数提供了一种处理列表(或集合)数据的高效方法,通过应用给定的函数对每个元素进行操作(map阶段),然后将结果聚合起来(reduce阶段),这种编程范式的特点在于其高阶函数的使用,即函数作为参数传递给其他函数,从而实现更加模块化和可组合的程序设计。
发展需求:随着互联网的快速发展和信息量的激增,传统的数据处理方法已无法满足需要处理海量数据的搜索引擎公司,Google便是其中之一,他们需要一种能够有效处理Web文档索引的系统,以支持其搜索引擎的运作,这直接促使了MapReduce模型的诞生,它能够将大规模数据处理任务分解为多个小任务,这些小任务可以并行处理,极大地提高了数据处理效率。
2、核心技术
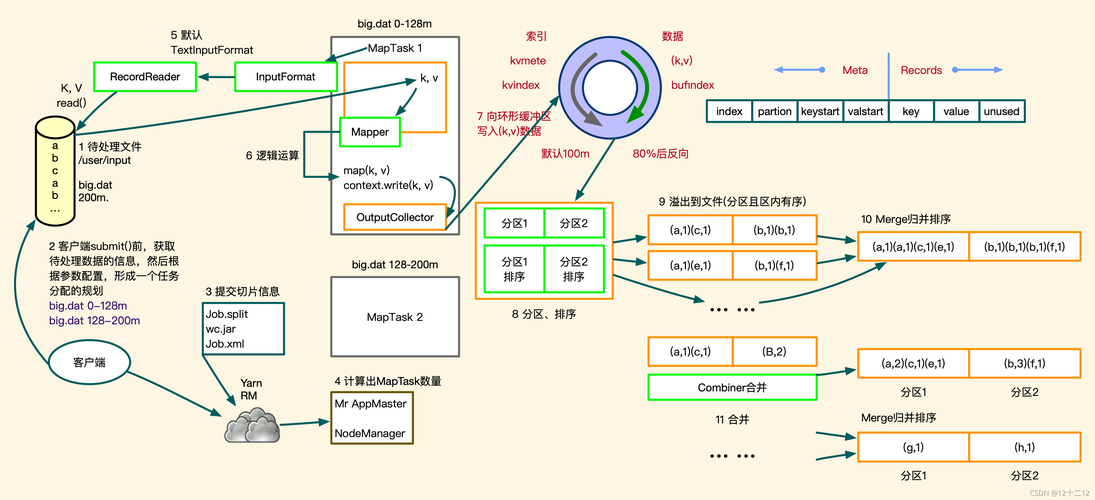
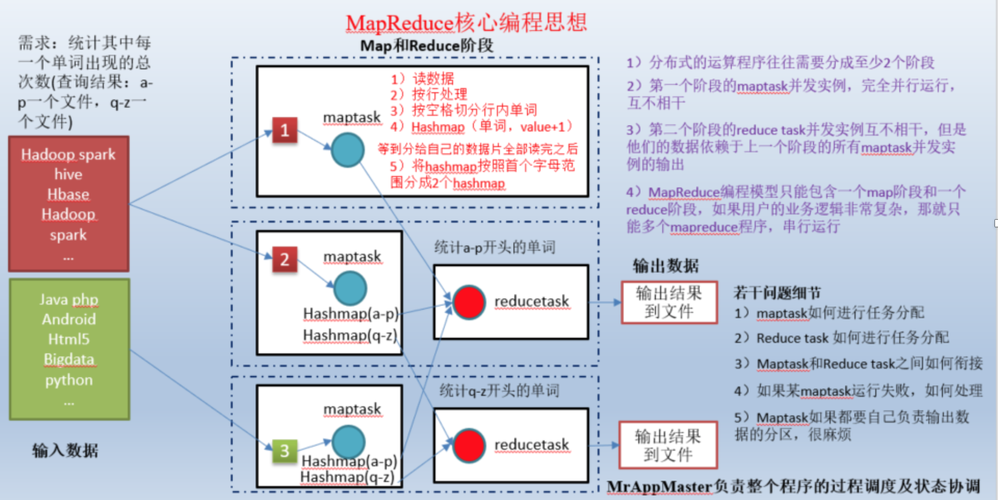
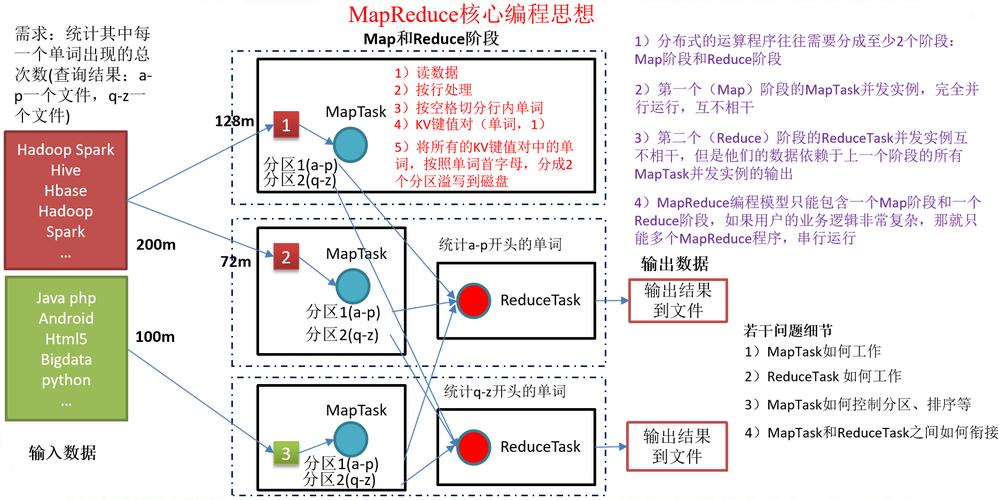
任务分解与并行执行:MapReduce的核心在于将大计算任务分解为多个小任务,这些小任务可以独立并行执行,在“Map”阶段,系统将输入数据分成小块,然后分别对每一块进行处理;在“Reduce”阶段,则是将Map阶段的输出结果进行汇总,得到最终的处理结果。
适用环境:MapReduce的设计初衷是应用于分布式环境,这使得它具有极高的可扩展性和容错性,在分布式系统中,硬件故障是常态,MapReduce通过将任务分解成可在多个节点上并行处理的小任务,有效避免了单点故障对整个系统的影响。
3、实现框架
Hadoop的贡献:Hadoop作为MapReduce的一个开源实现,极大地推动了这一模型的普及和应用,Hadoop项目包括一个分布式文件系统(HDFS)和一个实现MapReduce计算模型的编程框架,它允许开发者在大量廉价的硬件资源上执行MapReduce任务,而无需依赖昂贵的专用机器。
生态系统:随着Hadoop的流行,围绕它形成了一个完整的生态系统,包括数据仓库(如Hive)、数据处理(如Pig)、以及数据流处理(如Storm)等工具,这些工具进一步简化了大数据处理流程,使得非专业程序员也能轻松地编写和执行复杂的数据处理任务。
4、应用场景
Web文档索引:最初,MapReduce被用于Google的Web文档索引系统,通过并行处理数以亿计的网页,MapReduce显著缩短了索引构建的时间,从而提升了搜索引擎的效能。
大数据分析:MapReduce已被广泛应用于各种需要处理大规模数据集的场景,包括但不限于日志分析、商业智能、机器学习、科学研究等,它的强大之处在于能够处理结构化和非结构化的大数据,帮助企业和组织从海量数据中提取有价值的信息。
5、技术挑战
性能瓶颈:尽管MapReduce在处理大规模数据方面表现出色,但还存在一些性能瓶颈,特别是在数据读取和写入阶段,为了进一步提升性能,需要优化底层的文件系统和网络传输。
实时处理:MapReduce适合批处理,但在需要实时数据处理的场景下表现不佳,对于这类需求,可采用其他模型如Apache Storm或Apache Flink等,它们专门设计用于处理实时数据流。
了解MapReduce不仅仅是认识一个计算模型,更是理解当代大数据处理架构的入门,深入学习其设计理念和实现方式,有助于掌握数据科学和大数据工程的核心竞争力,值得注意的是,随着计算需求的多样化,单一的MapReduce模型已逐渐向更加灵活和高效的数据处理框架转变,例如Apache Spark等,它们在某些场景下提供了更优的性能和更丰富的功能。
MapReduce的思想来源及其技术实现不仅解决了海量数据处理的挑战,也极大推动了大数据技术的发展,从Google的论文到Hadoop的实践,再到各类新型数据处理框架的创新,MapReduce的理念不断深化与扩展,影响着数据驱动时代的前进方向。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/853792.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复