


在现代企业的数据架构中,大数据ETL(Extract, Transform, Load)过程扮演着至关重要的角色,这一过程涉及从各种数据源抽取数据,对这些数据进行清洗和转换,最终加载到数据仓库或数据湖中以供进一步分析,在这一背景下,Hadoop作为一种广泛使用的开源框架,为处理大规模数据集提供了强大的支持,本文将深入探讨大数据ETL在Hadoop环境中的应用及其实现方式。

ETL流程与Hadoop的结合
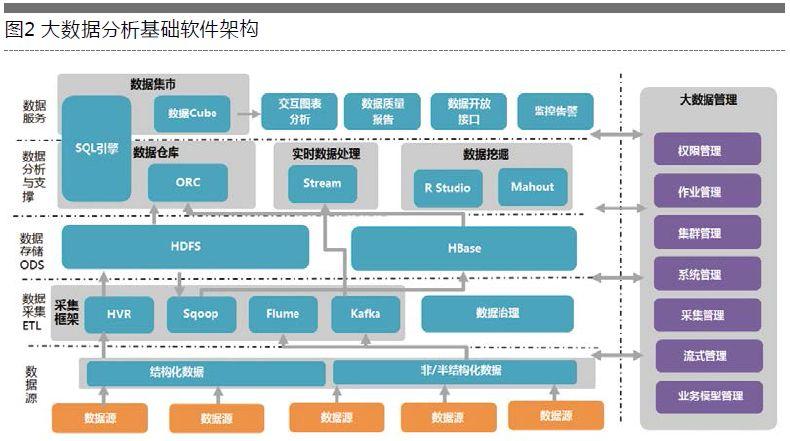
ETL作业在Hadoop环境中的实现主要依赖于其强大的存储和处理能力,Hadoop能够处理结构化和非结构化的大数据,这使得它成为执行ETL操作的理想平台,在Hadoop中,ETL作业可以通过编写MapReduce程序或使用更高级的工具如Apache Pig和Hive来实现,这些工具提供了一种高效的方式来处理和转换海量数据集。
数据抽取
数据抽取是从多个源系统中获取数据的过程,在Hadoop环境中,这通常涉及到从关系型数据库、NoSQL数据库、文件系统甚至是其他大数据存储系统中抽取数据,工具如Sqoop可以被用来从关系型数据库中导入数据到Hadoop,而Flume则可以用于收集和聚合来自多种源的日志数据。
数据转换
一旦数据被抽取到Hadoop环境中,下一步是数据转换,这个过程包括数据清洗、数据融合、数据过滤和数据扩充等操作,在Hadoop中,可以使用Hive来进行大规模的数据转换,它允许用户通过SQLlike的查询语言来操作数据,Pig Latin是另一种在Hadoop上进行数据转换的脚本语言,适用于探索性数据分析和转换。
数据加载
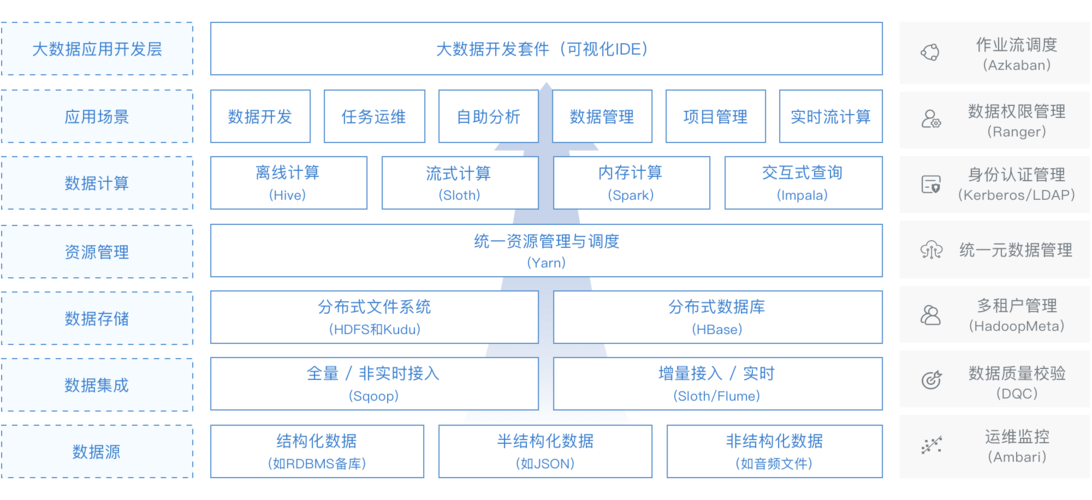
数据转换完成后,最后一步是将处理过的数据加载到目标系统中,这可能是一个数据仓库、数据湖或其他类型的存储系统,在Hadoop生态系统中,可以用MapReduce程序直接将数据写入到HDFS(Hadoop Distributed File System),或者使用工具如HBase进行更高级的数据处理和存储。
工具和技术
在大数据ETL过程中,有多种工具和技术可供选择,Kettle(Pentaho Data Integration)是一个开源的ETL工具,它支持连接到Hadoop并执行数据的导入导出操作,Talend也是一个流行的数据集成工具,提供了广泛的连接器和设计工具,方便用户在Hadoop环境中实现复杂的ETL作业。
为了确保ETL过程的效率,需要对Hadoop集群进行适当的配置和优化,这包括合理地分配资源,优化MapReduce作业设置,以及调整存储格式以提高I/O性能,采用高效的数据压缩技术可以减少存储需求和网络传输时间,进一步提升ETL作业的性能。
安全性和合规性
在处理敏感数据时,保证ETL过程的安全性和遵守相关法规是非常重要的,在Hadoop环境中,可以实施Kerberos认证来增强安全性,同时利用Apache Ranger或Sentry进行细粒度的访问控制,确保ETL作业遵循GDPR、HIPAA等数据保护法规也是设计ETL解决方案时必须考虑的因素。

成本管理
尽管Hadoop提供了成本效益较高的大数据处理方案,但ETL过程的设计和维护仍然需要投入相应的资源,企业应该评估不同工具和技术的成本效益比,选择最适合自己业务需求的ETL解决方案,考虑到硬件和运维成本,云基础设施上的Hadoop服务可能是一个经济有效的选择。
未来趋势
随着技术的不断进步,大数据ETL领域也在不断发展,Apache NiFi和StreamSets等现代化的数据流工具正在简化ETL过程,提供更加直观的用户界面和更强的数据处理能力,机器学习和人工智能的集成正在逐步改善ETL工具的自动化和智能化水平,从而提高效率和准确性。
通过以上分析,我们可以看出,在Hadoop环境下实现大数据ETL作业不仅可行,而且具有多方面的优势,通过选择合适的工具和技术,企业能够有效地处理和分析大量数据,从而获得宝贵的业务洞察。
相关问答FAQs
ETL在Hadoop中如何保证数据质量?
在Hadoop中保证数据质量需要采取多项措施,使用合适的数据抽取工具确保原始数据的准确性和完整性,在数据转换阶段应用数据清洗技术,如去重、空值处理、格式标准化等,以确保数据一致性,通过校验和验证步骤确保加载的数据符合预定的质量标准。
Hadoop上的ETL作业如何扩展以处理不断增长的数据量?
Hadoop本身就是为处理大规模数据集而设计的,具有良好的水平扩展性,当数据量增长时,可以通过增加集群节点的方式来扩展Hadoop的处理能力,优化ETL作业的设计,比如改进算法效率、使用更高效的数据格式(如Parquet或ORC),也可以提升处理大数据集的能力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/853722.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复