


由于您提供的内容不包含具体的信息或上下文,我无法直接生成一个摘要。如果您能提供详细的内容或者描述您想要摘要的文本,我将能够更好地帮助您。请分享您需要摘要的具体内容,谢谢!
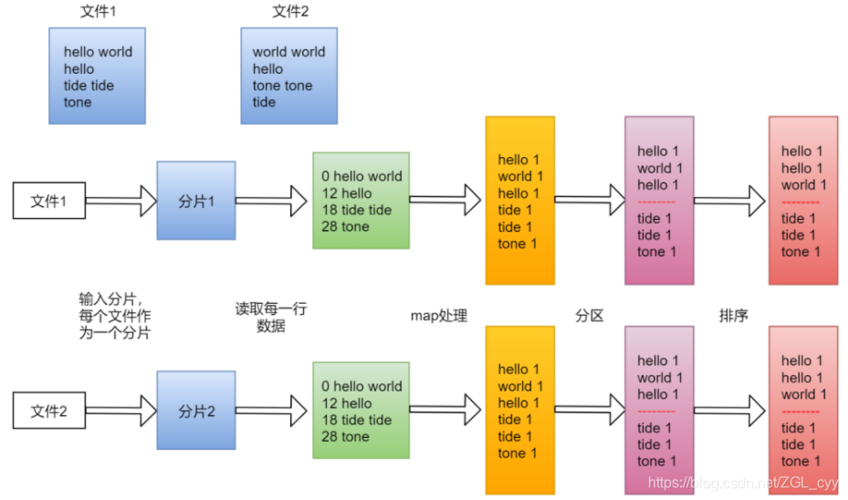
MapReduce 是一种编程模型,用于处理大量数据,在 MapReduce 中,任务被分成两个阶段:Map 和 Reduce,Map 阶段将输入数据拆分成多个独立的数据块,然后并行处理这些数据块,Reduce 阶段将所有 Map 阶段的输出合并成一个最终结果。


(图片来源网络,侵删)
下面是一个使用 Python 编写的 MapReduce 单词统计脚本的注释,这个脚本的主要目标是统计一个文本文件中每个单词出现的次数。
导入必要的库
from collections import defaultdict
import sys
Map 函数
def map_func(document, _):
# 初始化一个默认字典来存储单词计数
word_count = defaultdict(int)
# 读取文件内容
for line in document:
# 将每一行分割成单词
words = line.strip().split()
# 对每个单词进行计数
for word in words:
word_count[word] += 1
# 返回单词计数
return word_count.items()
Reduce 函数
def reduce_func(word, values):
# 对每个单词的出现次数进行累加
return (word, sum(values))
主函数
if __name__ == "__main__":
# 使用 MapReduce 库进行处理
MRJob.run() 在这个脚本中,我们首先导入了必要的库,然后定义了map_func 和reduce_func 函数。map_func 函数负责读取文档,并将每一行分割成单词,然后对每个单词进行计数。reduce_func 函数则负责对每个单词的出现次数进行累加。
在主函数中,我们使用MRJob.run() 来运行 MapReduce 任务,这个函数会自动处理 Map 和 Reduce 阶段的所有细节,包括数据的分发、收集和组合。
这个脚本的输入应该是一个或多个文本文件,每行包含一些单词,输出则是每个单词及其在所有输入文件中的总出现次数。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/853245.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复