


MapReduce是一种编程模型,用于处理和生成大数据集。JobControl是MapReduce中的一个组件,负责作业调度和管理。在Hadoop框架中,MapReduce通过将任务分解为多个小任务并并行处理,提高了数据处理速度和效率。
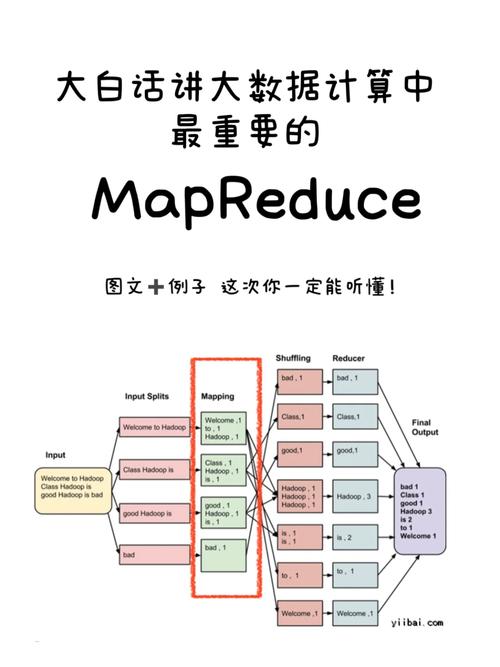
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对(keyvalue pair),在Reduce阶段,所有具有相同键的值被组合在一起,并应用一个规约函数以生成最终结果。

(图片来源网络,侵删)
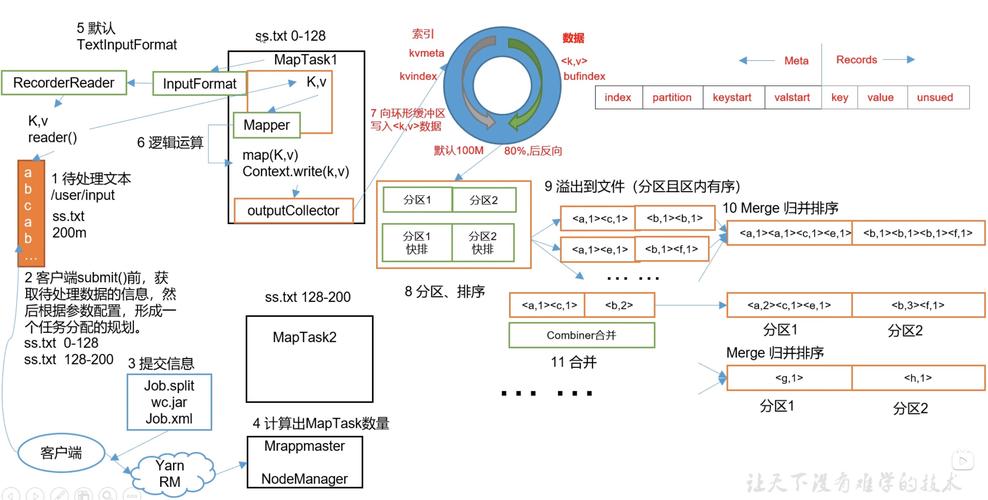
JobControl是Hadoop的一个组件,用于管理和监控MapReduce作业,它可以帮助你控制作业的执行顺序、优先级和失败恢复等。
下面是一个使用JobControl来管理MapReduce作业的示例代码:
from org.apache.hadoop.mapreduce import Job from org.apache.hadoop.mapreduce import Mapper, Reducer from org.apache.hadoop.conf import Configuration from org.apache.hadoop.fs import Path from org.apache.hadoop.io import IntWritable, Text class MyMapper(Mapper): def map(self, key, value, context): # Your mapping logic here pass class MyReducer(Reducer): def reduce(self, key, values, context): # Your reducing logic here pass if __name__ == '__main__': # Create a new configuration object conf = Configuration() # Set the job name and specify the input and output paths job_name = "My MapReduce Job" input_path = Path("/path/to/input") output_path = Path("/path/to/output") # Create a new job with the specified configuration job = Job(conf, job_name) # Set the mapper class and the reducer class job.setMapperClass(MyMapper) job.setReducerClass(MyReducer) # Set the input and output formats job.setInputFormatClass(TextInputFormat) job.setOutputFormatClass(TextOutputFormat) # Set the types for the key and value in the output job.setOutputKeyClass(Text) job.setOutputValueClass(IntWritable) # Set the input path and output path FileInputFormat.addInputPath(job, input_path) FileOutputFormat.setOutputPath(job, output_path) # Submit the job and wait for it to finish job.waitForCompletion(True)
在这个示例中,我们首先定义了一个名为MyMapper的Mapper类和一个名为MyReducer的Reducer类,我们在主程序中创建了一个新的作业配置对象,并设置了作业名称、输入路径和输出路径,我们指定了Mapper类和Reducer类,以及输入和输出格式的类型,我们提交了作业并等待其完成。
这只是一个基本的示例,实际的MapReduce作业可能需要更复杂的逻辑和配置,JobControl的具体用法取决于你使用的Hadoop版本和编程语言,上述示例使用的是Java语言和Hadoop的Java API。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/852977.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复