


在探讨MapReduce的各个类作用以及如何获取其它各个接口地址时,下面将详细介绍MapReduce的核心组件及其功能,并提供有关如何通过Hadoop和相关工具使用这些接口的信息。


MapReduce 核心组成及其作用
1、Mapper类
作用:Mapper类是MapReduce程序中负责映射过程的类,它继承自hadoop库中的Mapper类,通常重写map方法来处理输入数据,每次调用map方法时,它会接收一个键值对作为输入,并产出零个或多个键值对作为输出。
数据处理:在map方法中,可以对输入的keyvalue进行预处理,并将处理后的数据分发给下游的Reduce Task,这个过程是分布式和并行的,每个Mapper任务在不同的数据分片上独立运行。
2、Reducer类
作用:Reducer类负责Reduce阶段的任务,它接收Mapper产出的数据并进行汇总或聚合操作,Reducer同样需要重写reduce方法,以实现自定义的数据处理逻辑,Reducer的输出通常是最终结果或下一个处理阶段需要的中间数据。
聚合数据:Reducer会处理来自不同Mappers的所有相同key的输出数据,这常常涉及到复杂的计算和数据合并任务。
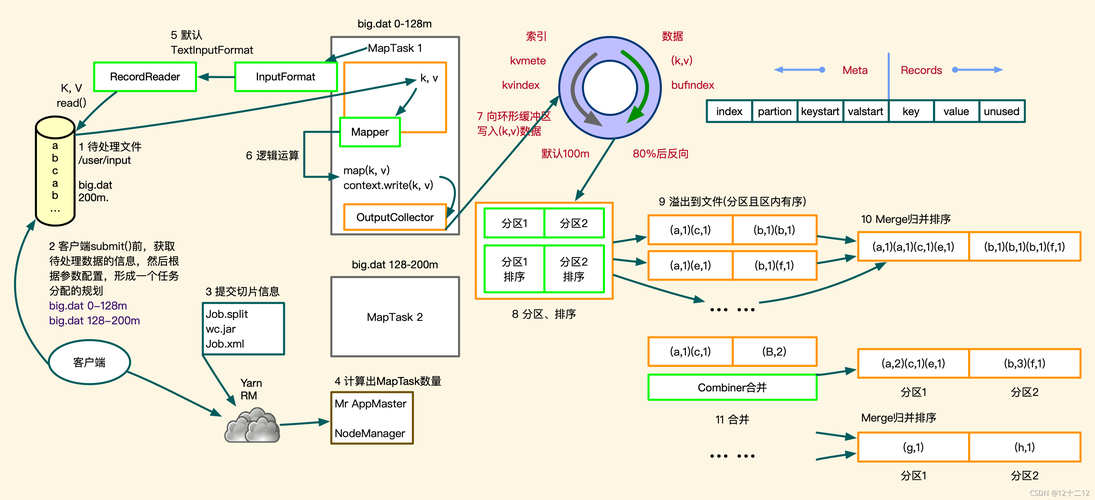
3、Partitioner接口
作用:Partitioner接口在MapReduce中扮演着数据分配的角色,其主要任务是根据key或value的值以及Reduce Task的数量,决定每对输出数据应该由哪个具体的Reduce Task处理,默认的Partitioner实现通常基于key的哈希值并以Reduce Task数量取模来决定数据的分配。
优化控制:通过实现自定义的Partitioner,可以优化数据处理的分布和负载均衡,进而提高整体的处理效率。
4、Task类
Map Task和Reduce Task:Task类在Hadoop中代表一个单独的执行单元,分为Map Task和Reduce Task,每个Task在一个称为slot的执行槽中运行,而Hadoop调度器负责将空闲的slots分配给这些Task,Map Task和Reduce Task分别在Map slot和Reduce slot中运行,有效利用集群资源。
资源管理:这种模式允许Hadoop有效地管理资源,根据需要动态地分配计算资源,并且平衡各个节点之间的负载。
获取MapReduce接口地址和使用方法
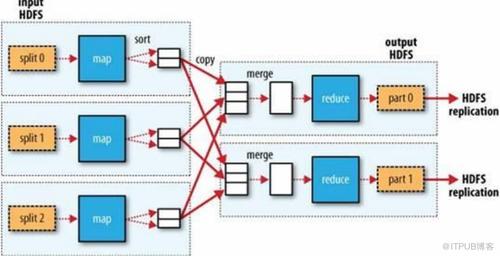
1、使用Hadoop Jar命令
操作方法:要运行MapReduce程序,需将其打包成JAR文件并通过hadoop jar命令提交到Hadoop集群,这个命令不仅支持MapReduce程序的执行,还带有众多选项来配置如输入输出路径、配置文件等参数。
具体操作:使用Maven或直接通过Hadoop提供的构建工具,编译并打包MapReduce程序,确保pom.xml中有正确的依赖配置,之后,可以通过命令行工具执行这个jar文件,使其分布式地运行在Hadoop集群上。
2、编写Map和Reduce函数
环境配置:在Hadoop的Java API中,可以通过实现定义好的接口来编写map和reduce函数,使用org.apache.hadoop.io.IntWritable等基本数据类型和格式,来适配Hadoop的数据读写需求。
实现业务逻辑:具体实现这些接口的方法时,开发者需要根据自己的业务需求来编写逻辑代码,这包括数据读取、处理、和写出操作,与Hadoop的文件系统(如HDFS)紧密相连。
3、依赖管理
添加依赖:在开发MapReduce应用时,必须添加相关的Hadoop依赖到项目中,使用Maven管理项目时,可以添加hadoopmapreduceclientcore等相关依赖,确保程序能够正常运行并接入Hadoop生态系统。
版本兼容:在选择依赖时,要注意Hadoop的版本兼容性,避免因版本不匹配导致的运行时错误。
通过上述结构和方法,可以高效地使用MapReduce进行大数据处理,这不仅涵盖了如何使用Hadoop生态系统中的MapReduce进行数据处理,同时也提供了接口地址获取的具体方式,确保开发者能够在Hadoop平台上高效实施自己的数据处理任务。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/852422.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复