


在探讨MapReduce的源码分析时,不仅需要理解其核心思想“分而治之”,还要深入了解其实现细节,本文将详细分析MapReduce的核心原理和源码结构,帮助读者从源代码层面全面理解MapReduce的工作流程和关键技术点。

源码结构和工作流程
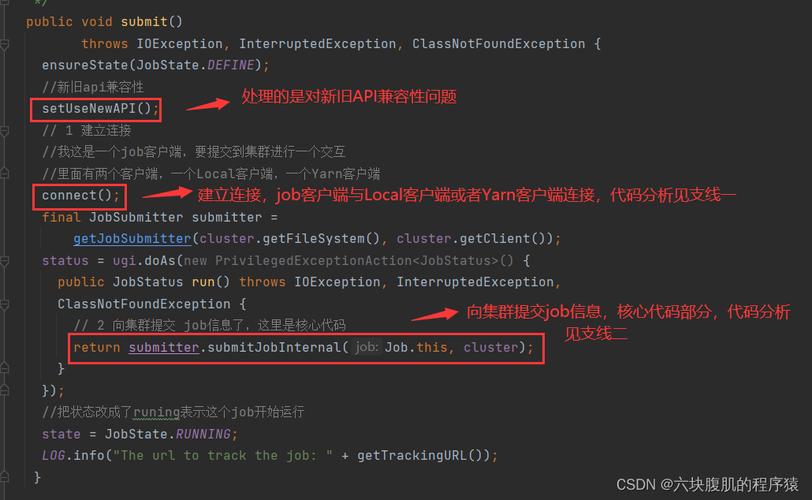
MapReduce程序主要由两部分组成:Map函数和Reduce函数,这两部分通过框架自动进行数据分发和结果收集,源码分析的首要任务是了解这两个函数如何被实现和调度的。
Map端源码分析: Map阶段的主要任务是将输入数据拆分成小的数据块,然后分别处理每个数据块生成键值对,这一过程通常由Mapper类实现,该类继承自MapReduceBase,重写了map方法,在map方法中,用户自定义逻辑用于处理输入记录并输出中间键值对。
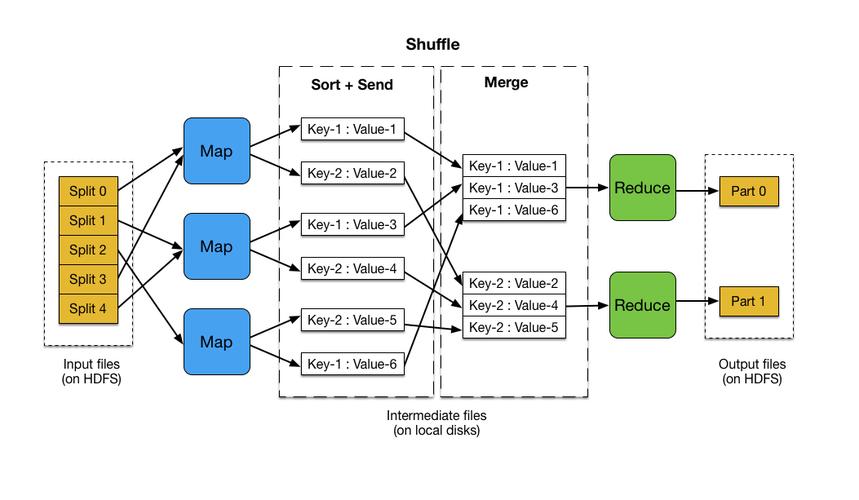
Shuffle and Sort阶段: 这个阶段是MapReduce中最为复杂的一个环节,主要负责数据的分区、排序和传输,在源码中,这部分涉及到环形缓存的使用(如上文提到可以在mapper里通过context.writer()进行debug),以及后续的排序和合并操作。
Reduce端源码分析: 经过Shuffle and Sort阶段后,数据被发送到各个Reduce任务,Reducer类同样继承自MapReduceBase,重写了reduce方法,在这个方法中,框架为每个唯一的键调用一次reduce方法,处理所有相关联的值。
Output阶段: Reduce任务的输出被写入到HDFS文件中,源码中这部分涉及到Hadoop的文件I/O系统,包括文件的创建、写入和关闭等操作。
关键组件和技术点
InputFormat和OutputFormat: MapReduce作业的输入和输出由InputFormat和OutputFormat接口定义,这两个接口的不同实现决定了数据的读取和写入方式,例如TextInputFormat用于文本数据,SequenceFileInputFormat用于序列化文件。
JobTracker和TaskTracker: MapReduce作业的调度和监控由JobTracker和TaskTracker完成,JobTracker负责作业的全局调度,而TaskTracker负责在各个节点上执行具体任务。
Hadoop分布式文件系统: 所有的MapReduce作业都依赖于HDFS来存储输入数据和输出结果,HDFS的高容错性和高吞吐量是MapReduce能够高效处理大规模数据集的关键。
性能优化策略
合理设置Map和Reduce的数量: 根据数据集的大小和结构,合理地设置Map和Reduce任务的数量可以显著提高作业的执行效率。
优化Shuffle和Sort阶段: 此阶段是MapReduce中最耗时的部分,通过调整环形缓冲区的大小和优化数据排序可以减少数据传输和排序的时间。
考虑数据本地化: Hadoop框架会尽可能地将任务调度到数据所在的节点,以减少网络传输的开销,在设计MapReduce作业时,应尽量利用这一点。

相关问答FAQs
Q1: MapReduce框架中,如果单个节点失败,如何处理?
A1: Hadoop框架设计了容错机制,当TaskTracker报告某个任务失败时,JobTracker会在另一个节点重新调度该任务执行。
Q2: MapReduce的性能瓶颈通常出现在哪些环节?
A2: 最常见的性能瓶颈出现在Shuffle和Sort阶段,因为这一阶段涉及到大量的数据传输和磁盘I/O操作,不当的配置如Map和Reduce任务数量不合理也会导致性能问题。
通过深入分析MapReduce的源码及其核心组件,我们不仅可以更好地理解其工作原理,还可以据此进行性能优化和故障排查,希望本文能为从事大数据处理的专业人士提供有价值的参考。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/851768.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复