


MapReduce是一个分布式计算的编程模型,主要用于处理和分析大规模数据集,该模型将复杂的计算任务分为两个主要阶段:Map阶段和Reduce阶段,通过这种分而治之的策略实现对庞大数据集的高效处理,下面将深入理解MapReduce模型的需求和功能:

1、MapReduce的起源和背景
起源:MapReduce最初由Google提出,旨在处理大规模数据集(大于1TB)的并行运算问题。
背景需求:随着互联网数据量的飞速增长,传统的数据处理方法已无法满足需要,MapReduce应运而生,为解决海量数据处理提供了新的思路。
2、MapReduce的基本原理
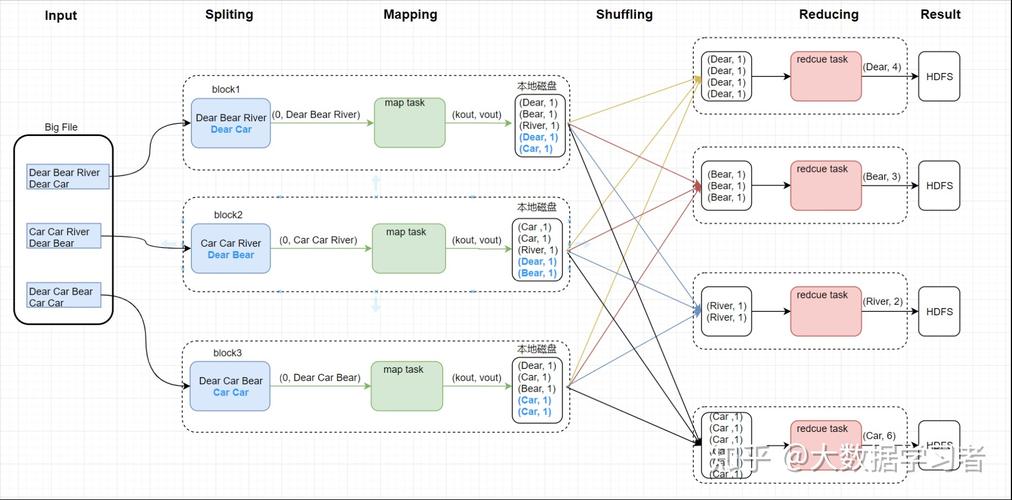
Map(映射):将输入数据切分成小块,由不同节点处理,每个节点处理后生成键值对形式的中间结果。
Reduce(归约):汇总所有Map阶段产生的中间结果,执行归纳操作,最终得出简化的结果集。
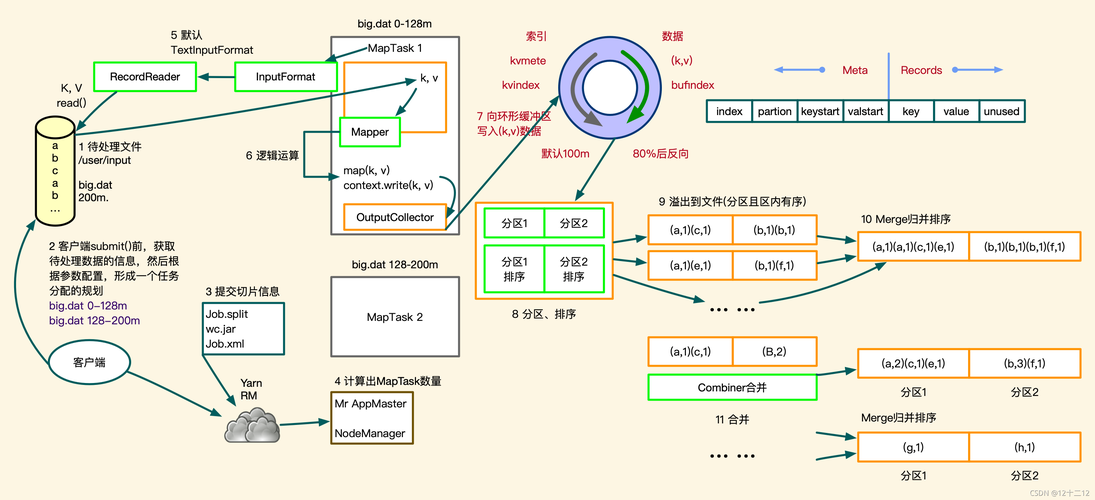
3、MapReduce的执行流程
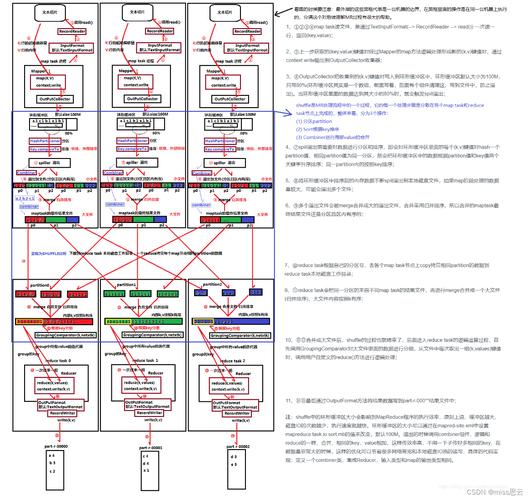
数据分割:将输入数据分割成小块,以便分布式处理。
任务分配:为每个节点分配Map任务,各节点并行处理分片数据。
本地计算:每个节点处理完数据后,将结果存储在本地,以减少数据传输成本。
结果汇总:通过Reduce阶段把所有中间结果汇总,进行最终的数据整合。
4、MapReduce的优势与应用
可扩展性:由于其分布式特性,MapReduce能够轻松扩展至大量节点上执行。
容错性:单点故障不会导致整个作业失败,系统可以自动重新分配任务。
灵活性:适用于各种数据处理任务,如日志分析、数据挖掘等。
5、MapReduce的技术细节
数据流:MapReduce作业涉及数据流的输入、处理和输出三个关键步骤。
并行处理:多个节点同时工作,显著提高数据处理速度和效率。
可以看出MapReduce不仅是应对大数据挑战的有效工具,也是分布式计算领域的一个里程碑,它通过简化编程复杂性,使得开发者能够轻松地处理海量数据,极大地推动了大数据技术的发展和应用,对于企业和科研机构而言,深入理解并有效利用MapReduce是释放数据价值、支持数据驱动决策的重要一环。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/850845.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复