


MapReduce是一种由Google提出的分布式计算框架,其核心功能是将用户编写的业务逻辑代码与自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上,Maven则是Apache下的一个纯Java开发的开源项目管理工具,可以对项目涉及的pom(Project Object Model)进行工程管理和项目依赖管理,利用Maven管理MapReduce项目,能提高开发效率和项目质量,具体分析如下:
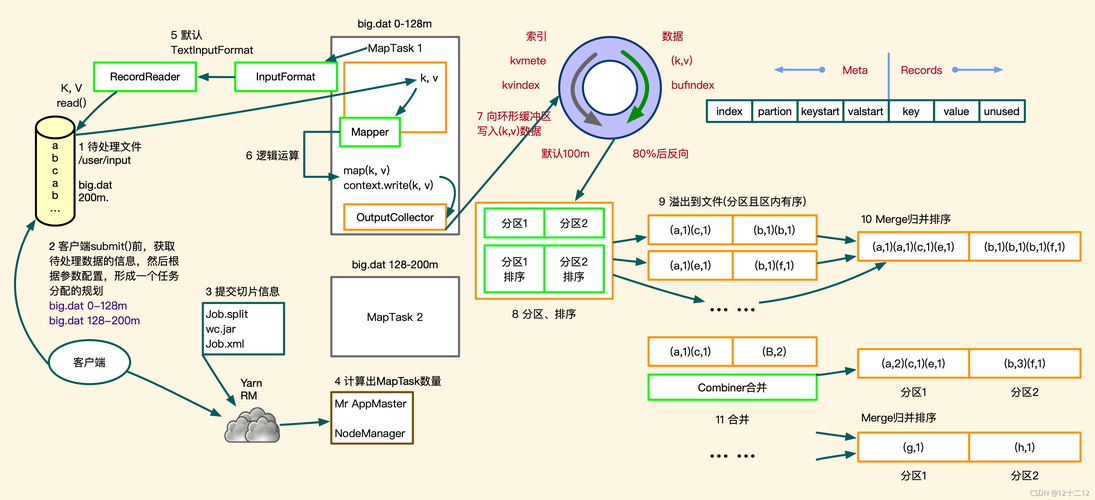

1、创建一个Maven项目
在IDEA中新建一个Maven项目:首先需要打开IDEA,新建一个Maven项目,这一步是初始化项目的基本操作,确保了项目的框架和基本结构。
2、导入Hadoop相关依赖
编辑pom.xml文件:在Maven项目中有一个非常重要的配置文件叫做pom.xml,这个文件定义了项目所需的所有依赖库以及项目自身的一些属性,为了使用MapReduce,需要在此文件中添加相关的Hadoop依赖,可以添加hadoopcommon、hadoophdfs、hadoopmapreduceclientcore等相关依赖,确保MapReduce程序能够正常运行。
3、编写MapReduce代码
Mapper阶段编程:在MapReduce框架中,数据的处理分为Map和Reduce两个阶段,在编写代码时,自定义的Mapper类需要继承一个父类,并实现map()方法,这个方法中包含了业务逻辑,输入数据为KV对的形式,输出也是KV对的形式,但类型可以自定义。
4、打包和运行

打包:编写完代码后,需要进行打包,在Maven中,只需要点击package,Maven就会自动根据pom.xml中的配置进行打包操作。
运行jar包:打包完成后,将生成的jar文件上传到Hadoop集群,然后在集群上运行这个jar文件,即可执行MapReduce任务。
值得一提的是,虽然MapReduce不适合处理实时数据、流失计算和有向图计算等任务,但它易于编程、扩展性好,并且适合处理PB级别的大数据,每个技术都有其适用场景,合理地利用它们的优势,可以更好地完成项目需求。
转移至一个与上述步骤相关的FAQs部分,以提供更具体的指导和帮助:
<u>FAQs</u>
Q1: 如何确定我应该使用哪个版本的Hadoop依赖?
A1: 应该使用与你所在Hadoop集群版本一致的依赖版本,可以通过询问集群管理员或者查看集群文档来确定这一点,如果不确定,可以使用最新的稳定版本尝试。
Q2: 如何在本地调试MapReduce程序而不用搭建Hadoop环境?
A2: 可以利用IntelliJ结合Maven进行本地运行和调试,具体方法是在pom.xml中添加相应的Hadoop依赖,然后在IntelliJ中配置好本地Hadoop运行环境,这样就可以在不搭建Hadoop环境的情况下进行MapReduce程序的开发和调试工作。
是使用Maven管理MapReduce项目的基本步骤和注意事项,希望能够对大家有所帮助,合理利用Maven的强大功能,可以大大提升MapReduce项目的开发效率和质量。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/850480.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复