


在大数据技术领域,MapReduce是一个广泛使用的编程模型,用于处理和生成大规模数据集,Partition(分区)作为MapReduce模型中一个关键步骤,承担了将数据从Map阶段传递到Reduce阶段的任务,下面将深入探讨MapReduce框架下的Partition机制,包括它的作用、类型、以及如何自定义Partitioner。
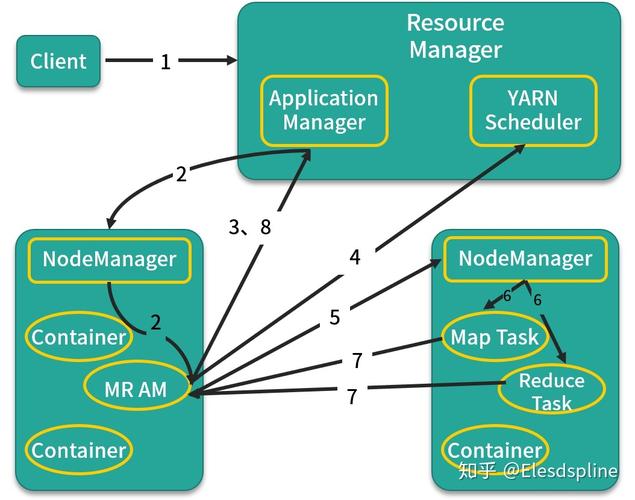

Partition的作用
1、数据传输的桥梁:Map阶段完成后,生成的中间数据需要被合理分配到各个Reduce节点上,而这一分配工作就是由Partition完成的,通过制定策略,Partition确保数据能够均匀且高效地分发到Reduce节点上。
2、负载均衡:为了使得数据处理更加高效,Partition机制力求将工作负载尽可能均匀地分配到不同的Reduce节点上,避免某些节点过载而影响整体的处理速度。
3、效率提升:除了要实现负载均衡外,Partition的操作也需快速完成,以确保整个数据处理流程的高效性。
Partition的类型与机制
1、默认Partitioner:Mapreduce框架提供了默认的Partitioner,即HashPartitioner,这种Partitioner使用哈希函数计算每条记录的分区号,公式为(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,这通常可以满足大部分场景的需求,但如果需要更细粒度的控制,可能需要自定义Partitioner。
2、自定义Partitioner:用户可以通过继承Partitioner类并实现getPartition方法来定义自己的分区策略,在某些情况下,可能需要根据特定的业务逻辑或数据特性进行分区,这时候自定义Partitioner就显得尤为重要。
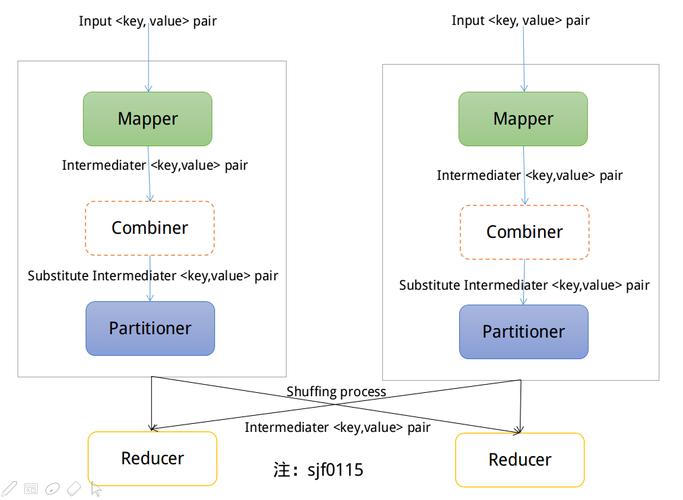
自定义Partitioner的步骤与案例
1、继承Partitioner类:创建一个新的类,继承自Partitioner,并指定K, V的数据类型,这两个类型分别代表Map输出的key和value的数据类型。
2、实现getPartition方法:在新的Partitioner类中重写getPartition方法,输入参数包括key、value及numReduceTasks(Reduce任务的数量),方法返回一个int值,表示分区号。
3、应用自定义Partitioner:在MapReduce作业配置时,通过setPartitionerClass方法设置自定义的Partitioner类,这样在作业执行时就会采用这个自定义的分区策略。
通过上述分析,可以看到Partition在MapReduce中扮演着至关重要的角色,它不仅关系到数据的传输和负载均衡,还直接影响到作业的执行效率,无论是选择默认的HashPartitioner,还是根据需求定制自己的Partitioner,理解其工作原理和实现方式对于优化MapReduce作业具有重要意义。
相关问答FAQs
Q1: 为什么需要自定义Partitioner?
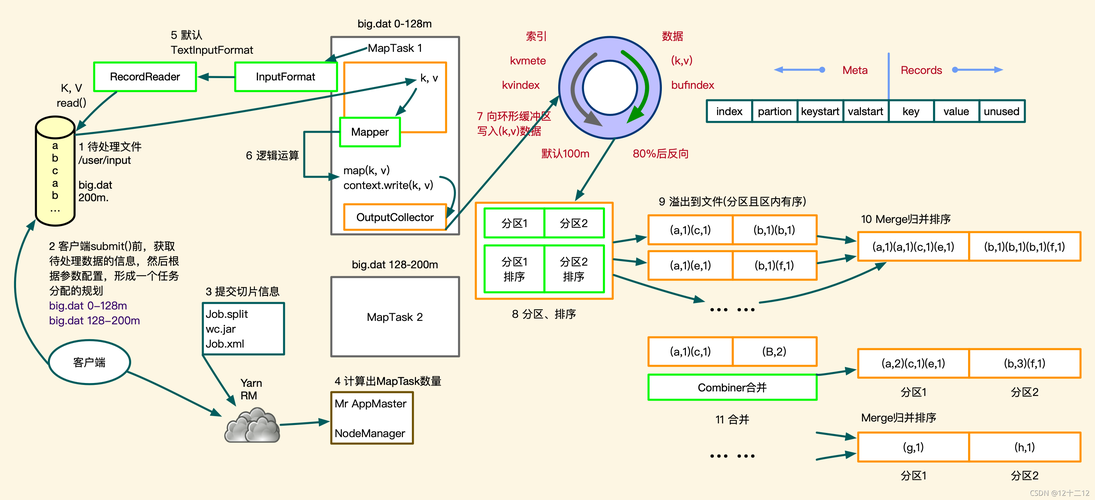
A1: 默认的HashPartitioner虽然能够满足大多数场景的需求,但在某些特定的情况下,比如需要按照特定的规则将数据划分到不同的输出文件中时,就需要通过自定义Partitioner来实现这一需求,自定义Partitioner允许用户根据自己的业务逻辑来控制数据分区的过程,从而实现更加精细化的数据管理和优化。
Q2: 自定义Partitioner有哪些注意事项?
A2: 自定义Partitioner时要确保getPartition方法的实现能够确保数据均匀分配,避免个别Reduce节点过载,要考虑分区策略对整体作业性能的影响,不合理的分区可能会导致数据处理效率降低,在进行分区时还要考虑异常情况的处理,保证分区过程的稳定性和可靠性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/850304.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复