


MapReduce 是一种编程模型,用于处理和生成大数据集。在 MapReduce 中实现 join 操作通常涉及将两个或多个数据集的键值对按照某个共享键进行合并。这需要自定义 map 和 reduce 函数来确保数据正确关联并聚合。
MapReduce是一种编程模型,用于处理和生成大数据集,在MapReduce中,数据被分成多个独立的块,这些块可以在集群中的不同节点上并行处理,Join操作是MapReduce中常见的一种操作,用于将两个或多个数据集按照某个键值进行合并。


(图片来源网络,侵删)
下面是一个使用MapReduce实现join_JOIN的示例:
1、我们需要定义一个Mapper函数,它将输入数据(来自两个表的行)映射到键值对,在这个例子中,我们将使用两个表A和B,它们具有相同的键字段(user_id)。
def mapper(key, value):
# key: user_id
# value: (table_name, row_data)
if value[0] == 'A':
yield key, ('A', value[1])
elif value[0] == 'B':
yield key, ('B', value[1]) 2、我们需要定义一个Reducer函数,它将Mapper输出的键值对进行归约,在这个例子中,我们将根据键值(user_id)将来自表A和表B的数据组合在一起。
def reducer(key, values):
# key: user_id
# values: [('A', row_data_from_A), ('B', row_data_from_B)]
table_a = []
table_b = []
for value in values:
if value[0] == 'A':
table_a.append(value[1])
elif value[0] == 'B':
table_b.append(value[1])
for a in table_a:
for b in table_b:
yield (key, a, b) 3、我们需要编写一个驱动程序来运行MapReduce作业,在这个例子中,我们将使用Hadoop Streaming API来执行MapReduce任务。
hadoop jar /path/to/hadoopstreaming.jar n input /path/to/input/dir n output /path/to/output/dir n mapper mapper.py n reducer reducer.py n file mapper.py n file reducer.py
这个命令将启动一个MapReduce作业,其中mapper.py和reducer.py是我们编写的Python脚本,输入数据应该位于/path/to/input/dir目录中,输出结果将被写入/path/to/output/dir目录。
注意:这个示例假设你已经安装了Hadoop并正确配置了环境,你需要根据实际情况调整输入和输出路径以及Python脚本的路径。
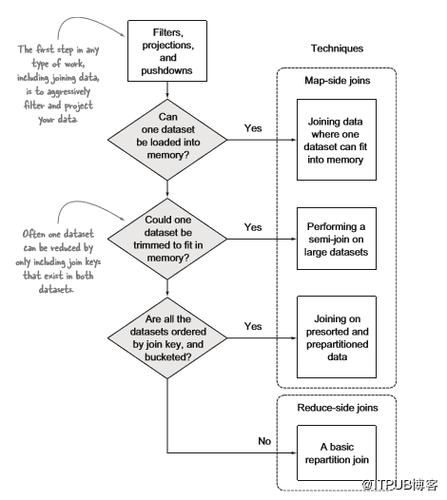
(图片来源网络,侵删)
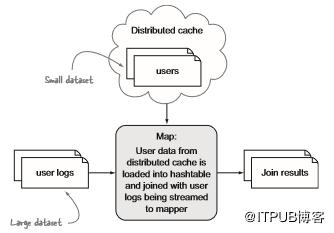
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/850222.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复