


MapReduce是一种用于并行计算的编程模型,最初由Google公司提出,用于大规模数据处理,在分布式计算环境中,节点故障和错误是不可避免的,容错机制对于保证MapReduce稳定运行和正确输出至关重要。
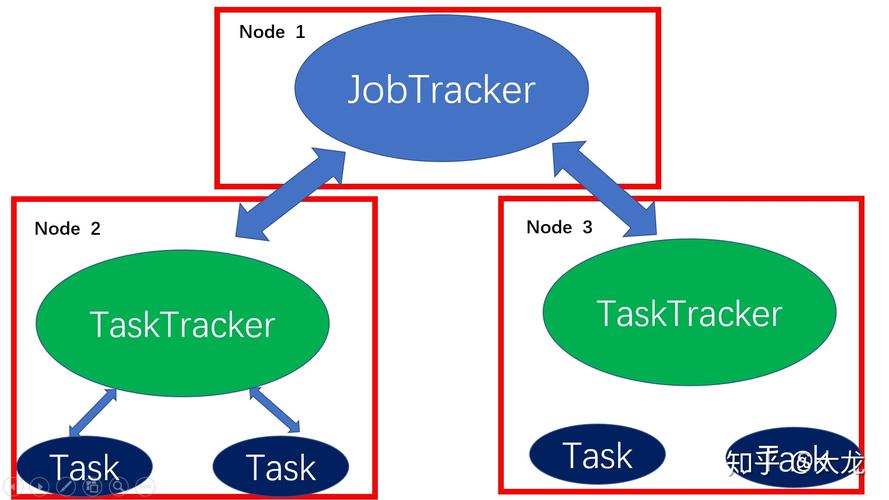

MapReduce的容错概念及重要性
1、容错概念
定义:在面对硬件故障、软件错误或其他意外情况时,系统仍能保持正常运行或迅速恢复的能力。
目的:确保作业能够成功完成,即使在出现故障的情况下。
2、容错的重要性
系统可用性:提高系统的可用性和稳定性,减少故障对系统的影响。
任务执行保障:减少故障对任务执行的影响,确保计算的顺利进行。
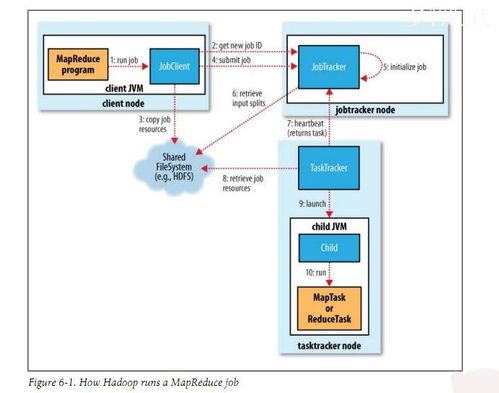
性能优化:通过统计故障发生的频率和原因,为系统的性能优化提供参考,减少故障的发生。
MapReduce中的容错设计原则
1、冗余存储和备份
数据副本:在不同节点上存储输入数据和中间结果的多个副本,防止单点故障和数据丢失。
实现方式:使用数据复制、数据分片和数据备份等技术手段。
2、故障检测和自动恢复
监控机制:通过心跳机制定期检测节点的状态,及时判定故障节点并触发故障恢复机制。
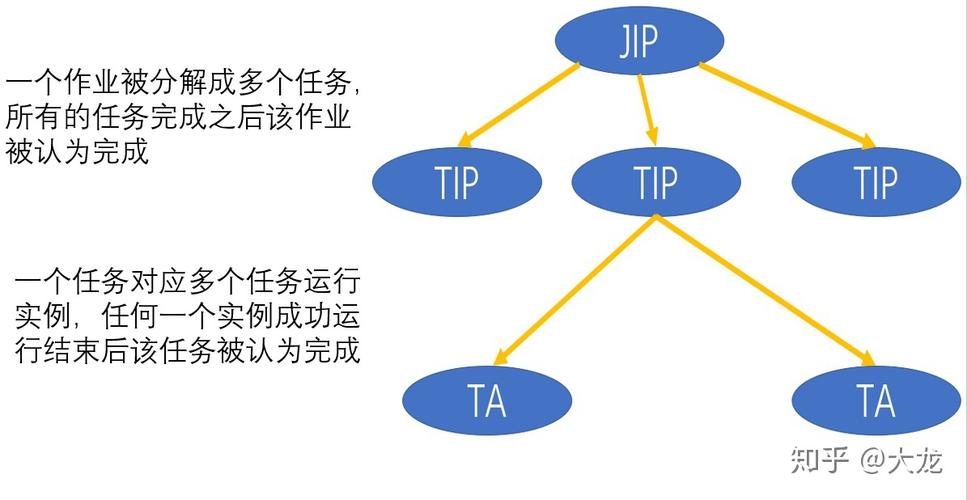
技术手段:使用心跳机制、监控系统和监视器等技术手段。
3、错误处理和失败重试
异常处理:MapReduce应具备检测任务执行错误和失败的能力,并能够尝试自动重试失败的任务。
技术手段:使用异常处理、失败重试和任务重新调度等技术手段。
MapReduce中的容错机制
1、任务重试机制
任务分配:在任务执行失败时,MapReduce框架会重新分配任务给其他节点执行,避免因某个节点故障导致任务失败。
最大重试次数:任务会一直重试直到成功或达到最大重试次数。
2、数据备份机制
数据恢复:在每个节点上备份数据,避免数据丢失或损坏,如果节点故障,MapReduce框架会从备份数据中恢复数据,重新分配任务。
3、故障检测与恢复
task失败:最常见的是用户代码抛出异常,JVM将向父节点报告错误并标记为失败,释放资源供其他任务使用。
Application Master Failure:如果Application Master失败,会尝试重新运行,最大尝试次数由属性控制。
YARN规定:独立的应用不能超过集群设定的最大尝试次数。
故障检测与定位方法
1、故障检测的作用与意义
提高系统可用性:快速发现问题,减少故障影响。
场景还原与排查:提供详细的故障信息,帮助开发人员定位问题。
2、故障检测的方法
心跳机制:定期检测节点状态,长时间未响应则判定为故障。
监控系统:使用监控系统和监视器来实时跟踪节点状态。
还有一些注意事项需要关注:
合理设置超时时间:确保任务可以在一定时间内完成,避免因超时而标记为失败。
配置最大重试次数:根据任务复杂度和实际需求合理设置最大重试次数,避免无效重试。
数据备份策略:选择合适的数据备份策略,确保数据安全同时避免过度占用存储资源。
监控系统稳定性:确保监控系统本身的稳定性,避免因监控失效导致未能及时发现故障。
MapReduce的容错机制主要包括任务重试机制、数据备份机制以及故障检测与恢复机制,这些机制共同作用,确保了MapReduce作业在出现故障时能够继续执行或迅速恢复,从而提高了系统的可用性和稳定性,在实际应用中,合理配置相关参数和策略,可以进一步提升MapReduce作业的容错能力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/846041.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复