


sql,SELECT DISTINCT 电话号码 FROM 来电记录表;,“在MySQL数据库中,处理重复数据是一项常见而重要的操作,尤其在客户信息、订单处理、或者来电记录等场景下,重复的数据不仅占用宝贵的存储资源,还可能影响数据的统计和分析准确性,本文将详细介绍如何在MySQL中识别并去除重复的来电数据。
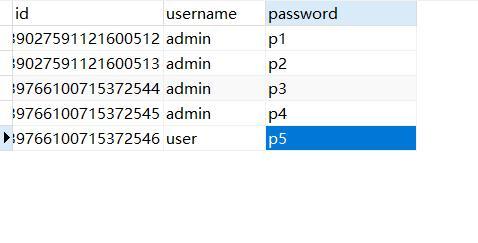

明确重复数据的定义及成因至关重要,在数据库中,重复数据通常指在同一张表中,某几个字段的内容完全相同的多条记录,这些重复记录可能是由于数据导入错误、用户重复提交、或是系统同步问题造成的。
我们将探讨几种在MySQL中检测和删除重复数据的有效方法,以一张名为call_records的表为例,其中包含id(主键)、caller_id(来电者ID)、callee_id(被叫者ID)和call_time(来电时间)等字段,我们的目标是删除那些caller_id和callee_id完全相同的重复来电记录,仅保留最新的一条记录(即call_time最新的一条)。
方法一:使用GROUP BY和MAX函数
一种直观的方式是利用GROUP BY结合聚合函数MAX来找到每组重复数据中call_time最新的记录,具体步骤如下:
1、查询最新的来电记录:
“`sql
SELECT caller_id, callee_id, MAX(call_time) as latest_call
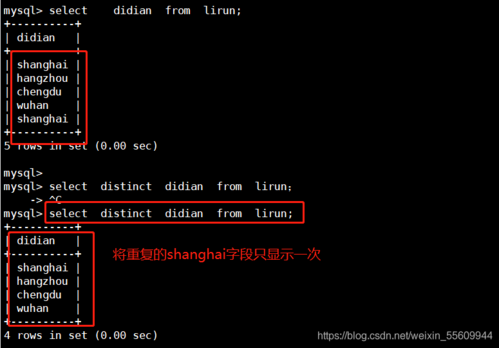
FROM call_records
GROUP BY caller_id, callee_id;
“`
该查询会返回每个caller_id和callee_id组合的最新来电时间。
2、删除多余的来电记录:
“`sql
DELETE cr1
FROM call_records cr1
INNER JOIN (
SELECT caller_id, callee_id, MAX(call_time) as latest_call
FROM call_records
GROUP BY caller_id, callee_id
) cr2 ON cr1.caller_id = cr2.caller_id AND cr1.callee_id = cr2.callee_id
WHERE cr1.call_time < cr2.latest_call;
“`
此操作通过JOIN条件定位到那些时间上非最新的重复来电记录,并将它们删除。
方法二:使用ROW_NUMBER()窗口函数
从MySQL 8.0开始,引入了窗口函数,提供了更灵活的处理方式。ROW_NUMBER()函数可以为每一行分配一个唯一的序号,通常是根据某个排序标准来的,以下是如何使用该方法的示例:
1、为每条记录分配序号:
“`sql
WITH RankedCalls AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY caller_id, callee_id ORDER BY call_time DESC) as row_num
FROM call_records
)
SELECT * FROM RankedCalls;
“`
这个查询将按照caller_id和callee_id分组,并根据call_time降序排列,最新的记录会被标记为1,其余递增。
2、删除多余的来电记录:
“`sql
DELETE FROM call_records
WHERE (caller_id, callee_id, call_time) IN (
SELECT caller_id, callee_id, call_time
FROM RankedCalls
WHERE row_num > 1
);
“`
这一步直接删除所有row_num大于1(即非最新记录)的来电记录。
方法三:使用INNER JOIN自我连接
另一种常见的方法是利用表的自我连接(Self Join),这种方法不需要窗口函数,适用于所有版本的MySQL。
1、查找需要删除的记录:
“`sql
SELECT first.
FROM call_records AS first
INNER JOIN call_records AS second ON first.caller_id = second.caller_id AND first.callee_id = second.callee_id
WHERE first.call_time < second.call_time;
“`
这个查询会找到那些与另一条记录具有相同caller_id和callee_id,但call_time较早的记录。
2、删除多余的来电记录:
“`sql
DELETE first
FROM call_records AS first
INNER JOIN call_records AS second ON first.caller_id = second.caller_id AND first.callee_id = second.callee_id
WHERE first.call_time < second.call_time;
“`
执行这条DELETE语句,即可移除所有非最新时间的重复来电记录。
方法四:利用临时表
当上述方法不适用或难以理解时,可以考虑使用临时表作为中介:
1、创建临时表并填充最新记录:
“`sql
CREATE TEMPORARY TABLE temp_calls AS
SELECT caller_id, callee_id, MAX(call_time) as latest_call
FROM call_records
GROUP BY caller_id, callee_id;
“`
2、删除原表中的多余记录:
“`sql
DELETE FROM call_records
WHERE (caller_id, callee_id) IN (SELECT caller_id, callee_id FROM temp_calls);
“`
3、从临时表中恢复保留的记录:
“`sql
INSERT INTO call_records (select * from temp_calls);
“`
别忘了删除临时表:
“`sql
DROP TEMPORARY TABLE temp_calls;
“`
上文归纳与实践建议
每种方法都有其适用场景和优缺点,使用窗口函数的方法简洁现代,但需要较高版本的MySQL支持;而使用GROUP BY和JOIN的方法则更加通用,但可能在大数据集上效率较低,选择合适的方法取决于具体的数据库版本、数据量大小以及个人偏好。
预防胜于治疗,为了减少未来重复数据的产生,可以采取以下措施:
数据验证与清洗:在数据导入前进行严格的验证和清洗,避免不符合规范的数据进入数据库。
设置数据库约束:合理使用唯一索引(UNIQUE)、主键(PRIMARY KEY)等约束,防止插入重复数据。
事务控制:在数据插入和更新操作中使用事务控制,确保数据的一致性和完整性。
有效管理和去除MySQL中的重复数据,不仅能提高数据质量,还能优化数据库性能,定期检查和维护数据,采用适当的策略和技术,将有助于保持数据的整洁和准确。
FAQs
Q1: 为什么在数据库中会出现重复数据?
重复数据的产生可能有多种原因,包括但不限于数据导入时的错误、系统同步问题、用户重复操作等,在来电记录的场景下,可能由于用户误操作或系统重复录入导致同一通话被记录多次,解决此类问题需要从源头控制数据质量,同时定期进行数据清理。
Q2: 删除重复数据后如何确认操作成功?
删除操作后,可以通过简单的查询来验证是否还有重复数据存在,可以使用前面提到的GROUP BY和COUNT的组合来检查特定字段的重复数是否超过1,比较删除前后的记录数量也是一种快速的方法,如果处理得当,删除操作后的记录数应该少于原始数量,且不再存在重复项。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/845910.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复