

MapReduce经典案例与场景


MapReduce是一种分布式并行编程模型,是Hadoop核心子项目之一,本文将详细介绍MapReduce的经典案例和应用场景。
MapReduce环境搭建
在开始编写MapReduce程序之前,需要搭建好Hadoop 3.3.5环境和Eclipse IDE,在Eclipse中搭建MapReduce环境需要安装hadoopeclipseplugin插件,并正确配置Hadoop集群连接。
1. 倒排索引
倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎,它提供了一种根据内容查找文档的方式。
Map阶段:读取文本文件,拆分单词,并形成<单词,文档名:出现次数>的键值对。
Combine阶段(可选):在Map端进行局部合并,减少数据传输量。
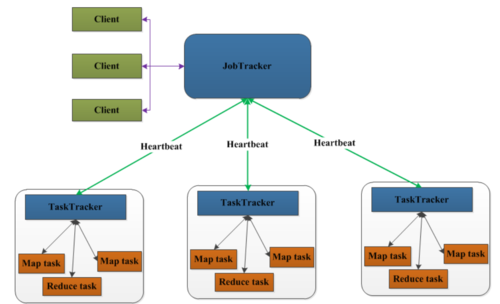
Reduce阶段:合并所有Map阶段的输出,汇总每个单词在所有文档中的出现次数,并生成最终的倒排索引。
实现细节:通过MapReduce实现倒排索引时,通常使用combine作为中间过渡步骤来实现,这样可以有效地减少网络传输的数据量,提高整体处理效率。
2. 数据去重
数据去重是一个常见的需求,MapReduce框架能够高效地完成这一任务。
Map阶段:读取数据,以唯一的数据项作为键输出。
Reduce阶段:对相同的键进行去重处理,只保留一个记录。
实现细节:在Map阶段,通过确保每个数据项唯一地映射到一个键上,可以在Reduce阶段直接进行去重操作,这种方法简单高效,适用于大规模数据集。
3. TopN
TopN问题也是大数据处理中的常见需求,例如找出出现频率最高的前N个单词。
Map阶段:类似于倒排索引的Map阶段,统计每个单词的出现次数。
Reduce阶段:对所有单词按出现次数进行排序,并输出前N个结果。
实现细节:在Reduce阶段,可以使用优先队列或其他数据结构来维护TopN的记录,以保证在处理大量数据时的效率。
MapReduce优缺点归纳
优点:易编程、良好的扩展性、高容错性、适合处理PB级以上的海量数据。
缺点:不擅长实时计算、流式计算和复杂的DAG计算。
相关问答FAQs
1、Q: MapReduce适合处理哪些类型的任务?
A: MapReduce非常适合处理大规模数据集上的离线批处理任务,如数据统计、数据分析和数据转换等,它的优势在于可以分布到多个节点上并行执行,从而高效地处理海量数据。
2、Q: 为什么MapReduce不适合实时计算?
A: MapReduce的设计是为了处理静态数据集,并且其运算过程涉及大量的磁盘IO操作,因此延迟较高,无法满足实时计算的毫秒级或秒级响应要求。
归纳而言,MapReduce作为一种经典的分布式并行编程模型,其在处理大规模数据集方面的高效性和易用性使其成为大数据分析领域的重要工具,尽管在实时计算和流式计算方面存在局限,但其在批处理任务中的表现仍然不可替代。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/845901.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复