

执行大数据量的shuffle过程时Executor注册shuffle service失败

在处理大规模数据集时,Shuffle过程是Spark作业中常见的性能瓶颈,当数据量达到数十T字节级别时,Shuffle过程的复杂性及其对资源的需求急剧增加,常常导致Executor在尝试注册Shuffle Service时出现超时或失败的问题,这不仅影响了作业的执行效率,还可能导致整个任务的失败,下面将探讨这一问题的原因及解决方案。
问题描述与核心原因
在大数据Shuffle过程中,每个Executor需要在Shuffle Service中注册以参与数据处理,当处理的数据量极大时,Shuffle过程的资源消耗也随之增加,主要包括CPU、内存、磁盘I/O以及网络带宽,这种高负载状态可能导致Shuffle Service无法及时响应Executor的注册请求,尤其是在大量Executors竞争激烈地访问有限资源的情况下。
技术细节与故障排查
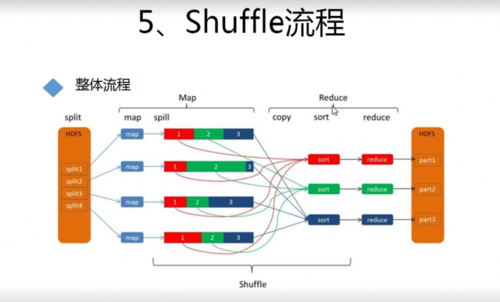
1、Shuffle过程详解: Shuffle的本质是数据的重分区和移动过程,在Map阶段,Executors执行数据的初步处理和局部聚合,然后通过Shuffle Write将数据暂存到磁盘;Reduce阶段则需要从这些暂存文件中拉取需要的数据进行最终处理,这一过程涉及大量的磁盘读写和网络传输操作,极易成为性能瓶颈。
2、资源竞争与配置问题: 在大数据量处理场景下,Executors之间的资源竞争尤为激烈,如果系统资源配置不当(如内存或CPU资源限制),会直接影响Shuffle过程的效率,Shuffle过程中的超时设置和重试机制也是关键因素,根据相关文档,Executor注册Shuffle Service的超时时间为5秒,最多重试3次,这种严格的超时限制可能在高负载情况下造成注册失败。
3、Shuffle Service的服务压力: Shuffle Service在管理大量Executors注册和数据协调时,面临着巨大的服务压力,尤其在数据量巨大时,Service不仅要处理来自Executors的注册请求,还要协调数据的流动和存储,很容易出现过载状态。
解决策略与优化建议
1、调整资源配置: 增加Executors的资源配额,特别是内存和CPU,可以提高其处理能力和响应速度,适当增加spark.yarn.executor.memoryOverhead和spark.yarn.executor.cpu可以缓解资源限制带来的压力。
2、调整Shuffle超时与重试机制: 考虑适当延长Shuffle Service的注册超时时间和增加重试次数,这可以通过修改Spark配置参数实现,例如调整spark.shuffle.service.enabled参数为true,确保Shuffle Service处于可用状态,并调整spark.network.timeout和spark.network.maxRetries来优化网络传输的可靠性。
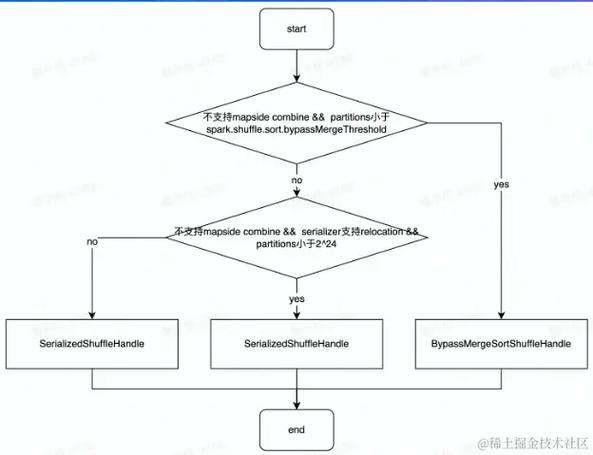
3、采用高效的Shuffle机制: Spark 2.0及以上版本推荐的Sort Based Shuffle比Hash Based Shuffle更高效,它减少了中间文件的数量,优化了数据排序和压缩过程,可以通过设置spark.shuffle.manager为SHUFFLE_MANAGER来启用。
4、细粒度的资源管理: 动态资源分配(dynamic allocation)和任务调度(task scheduling)的优化可以有效应对数据倾斜和资源不均的问题,配置参数spark.dynamicAllocation.enabled和spark.task.scheduler.mode能够实现更灵活的资源管理策略。
处理大数据量时的Shuffle挑战需要综合考虑系统资源配置、架构优化和问题诊断等多方面因素,通过上述措施,可以显著提高Spark处理大规模数据集时的性能和稳定性。
FAQs
Q1: Shuffle过程中主要会遇到哪些性能瓶颈?该如何解决?
答:Shuffle过程中常见的性能瓶颈包括磁盘I/O、网络传输和数据序列化,解决这些问题的方法包括采用更高效的Shuffle机制(如Sort Based Shuffle)、优化数据序列化方式(如使用Kryo序列化),以及调整Shuffle内存和缓存设置来减少磁盘操作。
Q2: 如何避免因Executor注册超时而引起的Shuffle失败?
答:可以增加Shuffle Service的超时时间,使其有更长的时间窗口处理注册请求;通过增加资源配额(如内存和CPU)来提升每个Executor的处理能力;适当增加任务的重试次数,以提高整体任务的完成率,这些措施可以通过调整Spark的配置参数来实现,例如spark.shuffle.service.enabled、spark.network.timeout等。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/845897.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复