


简介
Docker是一种流行的容器化技术,它允许开发者将应用程序及其依赖项打包在一个独立的容器中,这种技术的优势在于其可移植性、隔离性和易维护性,特别适用于机器学习项目的部署和分发,本文将详细介绍使用Docker实现机器学习端到端场景的全过程。
准备工作
在开始之前,确保你已经安装了Docker,并对Docker的基本命令有所了解,需要准备一个机器学习模型,这里以Python的Flask框架为例进行说明。
开发模型和Web服务
假设你已经有了一个训练好的机器学习模型(如your_trained_model.pkl),你需要创建一个Web服务来接收HTTP请求并返回预测结果,以下是一个简化的示例代码:
from flask import Flask, request, jsonify
import pickle
import numpy as np
app = Flask(__name__)
加载机器学习模型
model = pickle.load(open('your_trained_model.pkl', 'rb'))
@app.route('/predict', methods=['POST'])
def predict():
try:
data = request.get_json()
preprocessed_data = np.array(data['input']).reshape(1, 1)
prediction = model.predict(preprocessed_data)
return jsonify({"prediction": prediction.tolist()})
except Exception as e:
return jsonify({"error": str(e)})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=2023) 这段代码创建了一个基本的Flask应用,该应用接收包含输入数据的POST请求,通过预处理和模型预测,然后返回预测结果。
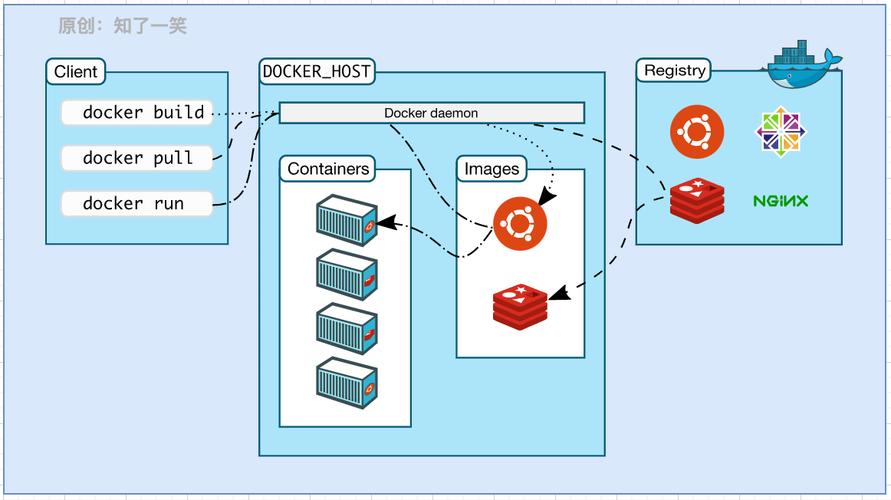
创建Docker镜像
需要一个Dockerfile来构建你的Docker镜像,以下是一个基本示例:
FROM python:3.8slim WORKDIR /app COPY requirements.txt requirements.txt RUN pip install r requirements.txt COPY . /app EXPOSE 2023 CMD ["python", "app.py"]
这个Dockerfile基于Python 3.8镜像,设置工作目录为/app,安装所需的依赖包,复制当前目录下的所有文件到容器内的工作目录,并暴露2023端口,指定运行app.py作为容器启动时执行的命令。
构建和运行容器
有了Dockerfile,接下来构建并运行Docker容器:
docker build t my_ml_app . docker run p 2023:2023 v /path_to_your_model:/app/your_trained_model.pkl my_ml_app
第一个命令会构建一个名为my_ml_app的Docker镜像,第二个命令则创建一个新容器并运行该镜像,通过v参数将本地模型文件挂载到容器中,这样在容器内部就可以直接使用该模型。
你可以通过浏览器或其他HTTP客户端访问http://localhost:2023/predict,发送POST请求进行模型预测。
部署到云平台
如果你想将这个应用部署到云平台(例如阿里云或华为云),流程类似,需要在云平台上创建一个虚拟机实例,安装Docker,然后重复上述构建和运行容器的过程,确保云平台的防火墙规则允许外部访问容器的端口。
许多云平台提供容器服务,例如阿里云的容器服务和华为云的容器引擎,这些服务可以更便捷地管理和部署Docker容器。
注意事项
数据持久化:如果需要持久化模型或者预测结果,可以使用Docker的卷(volume)功能,将数据保存在宿主机的指定路径。
性能优化:根据模型的大小和预测请求的并发量,需要调整Docker容器的CPU和内存配置,确保性能稳定。
安全考虑:在公开访问Docker服务时,需要设置合适的身份验证和加密措施,保护API不被未经授权的访问。
相关FAQs
1、如何在Docker容器中使用GPU进行机器学习模型训练?
答:需要使用支持GPU的Docker镜像,例如nvidia/cuda,在启动Docker容器时,通过gpus all参数来使容器内的应用程序能够访问主机上的GPU,确保在宿主机上安装了NVIDIA驱动程序和nvidiacontainertoolkit。
2、如何将机器学习模型从开发环境转移到生产环境?
答:使用Docker可以简化这一过程,在开发环境中完成模型的训练和测试后,将其与应用程序代码一起打包到一个Docker镜像中,通过在同一个Docker镜像上进行测试和部署,可以确保环境一致性,在生产环境中,只需部署相同的Docker镜像,并通过容器管理工具进行监控和管理。
通过Docker实现机器学习的端到端场景不仅提高了开发效率,也降低了环境配置和部署的复杂性,无论是在本地服务器还是在云平台上,Docker都是机器学习项目的理想选择。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/845743.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复