


在配置MapReduce Job基线时,需关注作业串联。确保任务按依赖顺序执行,优化资源分配与调度策略以提高效率。监控性能指标,调整参数以达到最优运行效果。
MapReduce Job串联配置MapReduce Job基线


(图片来源网络,侵删)
1、配置环境
安装Hadoop集群
配置Hadoop环境变量
检查Hadoop集群状态
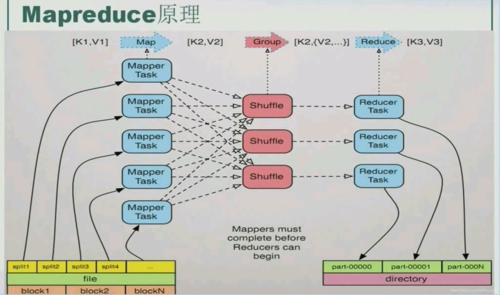
2、编写Mapper类
继承org.apache.hadoop.mapreduce.Mapper类
重写map方法,实现数据处理逻辑
(图片来源网络,侵删)
3、编写Reducer类
继承org.apache.hadoop.mapreduce.Reducer类
重写reduce方法,实现数据聚合逻辑
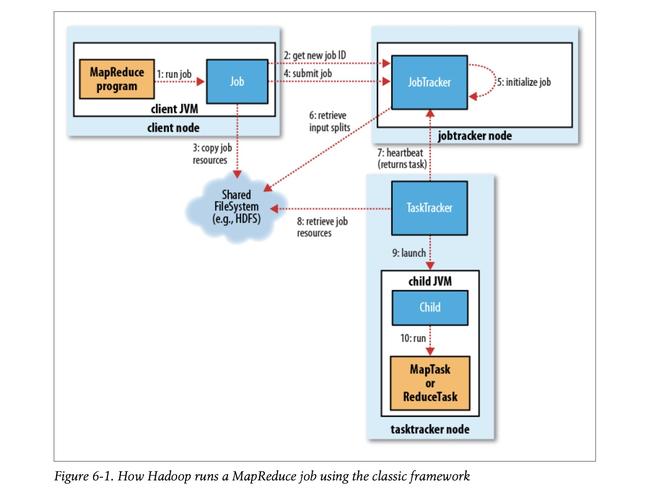
4、编写Driver类
设置输入输出路径
设置Mapper和Reducer类
设置作业名称和作业类型
(图片来源网络,侵删)
提交作业到集群运行
5、运行MapReduce作业
使用命令行工具提交作业
查看作业运行日志
获取作业结果
6、优化MapReduce作业
调整分区策略
调整Reducer数量
调整Map和Reduce任务的并行度
使用Combiner进行局部聚合
7、监控MapReduce作业
使用Hadoop Web界面查看作业状态
使用日志分析工具查看作业性能指标
使用资源管理器查看集群资源使用情况
8、故障排查与处理
分析作业失败原因
调整资源配置
修复代码错误
重新提交作业
9、MapReduce作业示例
| 序号 | 步骤 | 说明 |
| 1 | 配置环境 | 安装Hadoop集群,配置环境变量,检查集群状态 |
| 2 | 编写Mapper类 | 继承Mapper类,重写map方法,实现数据处理逻辑 |
| 3 | 编写Reducer类 | 继承Reducer类,重写reduce方法,实现数据聚合逻辑 |
| 4 | 编写Driver类 | 设置输入输出路径,设置Mapper和Reducer类,设置作业名称和类型,提交作业到集群运行 |
| 5 | 运行MapReduce作业 | 使用命令行工具提交作业,查看作业运行日志,获取作业结果 |
| 6 | 优化MapReduce作业 | 调整分区策略,调整Reducer数量,调整并行度,使用Combiner进行局部聚合 |
| 7 | 监控MapReduce作业 | 使用Hadoop Web界面查看作业状态,使用日志分析工具查看作业性能指标,使用资源管理器查看集群资源使用情况 |
| 8 | 故障排查与处理 | 分析作业失败原因,调整资源配置,修复代码错误,重新提交作业 |
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/845293.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复