


MapReduce引擎无法查询Tez引擎执行union语句写入的数据


问题描述
在使用Hadoop的MapReduce和Tez引擎时,用户可能会遇到一个问题:当使用Tez引擎执行包含UNION操作的SQL语句并将结果写入到HDFS或其他存储系统时,MapReduce引擎无法直接查询这些数据,这是因为MapReduce和Tez引擎在处理数据的方式上有所不同,导致它们之间的数据不兼容。
解决方案
方案1: 使用相同的执行引擎
优点: 避免数据格式转换,提高查询性能。
缺点: 如果业务逻辑需要同时使用MapReduce和Tez引擎,可能需要额外的开发工作来确保两个引擎之间的兼容性。
方案2: 将Tez引擎生成的数据转换为MapReduce可读的格式
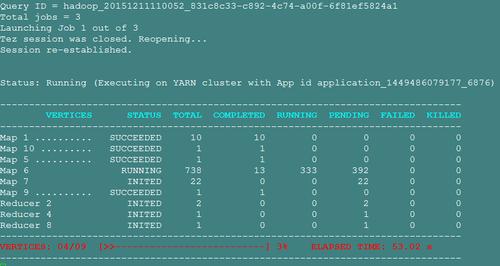
优点: 可以在MapReduce引擎中直接查询数据,无需额外的转换步骤。
缺点: 可能需要额外的开发工作来实现数据的转换,并可能影响查询性能。
方案3: 使用其他工具或框架进行查询
优点: 可以绕过MapReduce的限制,直接查询Tez引擎生成的数据。
缺点: 可能需要学习新的工具或框架,并可能需要额外的配置和管理成本。
示例代码(方案2)
假设我们有一个Tez引擎执行的包含UNION操作的SQL语句,我们可以将其结果转换为MapReduce可读的格式,例如Parquet或Avro,以下是一个简化的示例代码:
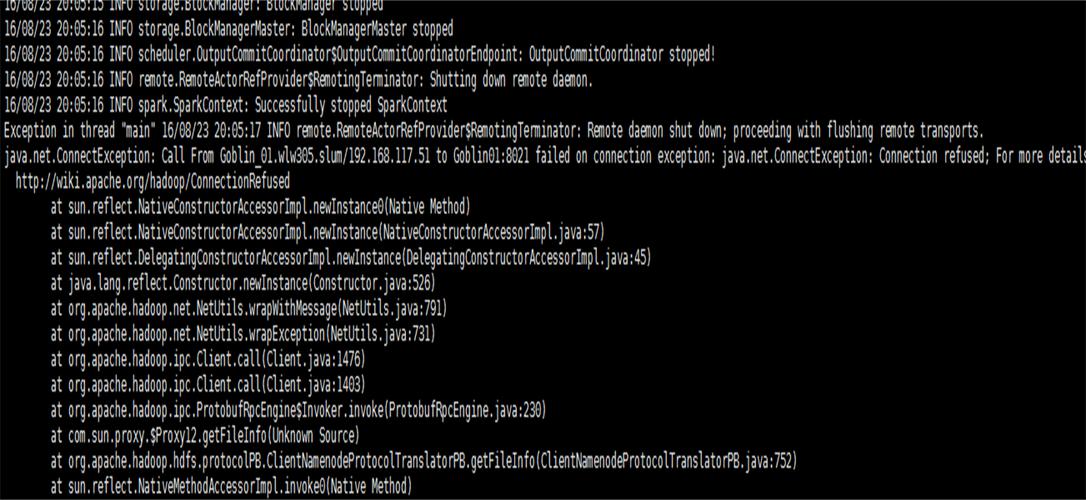
from pyspark.sql import SparkSession
创建SparkSession
spark = SparkSession.builder n .appName("TezToMapReduce") n .getOrCreate()
读取Tez引擎生成的数据(假设为CSV格式)
tez_data = spark.read.csv("hdfs://path/to/tez_output", header=True, inferSchema=True)
对数据进行处理(执行UNION操作)
processed_data = tez_data.union(another_dataframe)
将处理后的数据转换为MapReduce可读的格式(Parquet)
processed_data.write.parquet("hdfs://path/to/mapreduce_input")
关闭SparkSession
spark.stop() 在这个示例中,我们首先创建一个SparkSession,然后读取Tez引擎生成的数据,我们对数据进行处理(执行UNION操作),并将处理后的数据转换为MapReduce可读的格式(Parquet),我们关闭SparkSession。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/844640.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复