


MapReduce 优势和产品优势
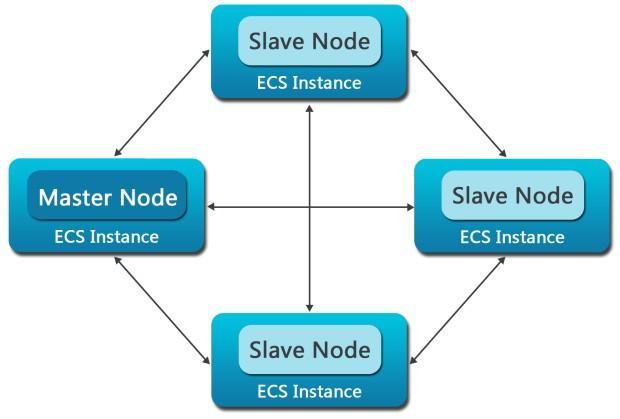

MapReduce是一种强大的大数据处理和分布式计算模型,它能够高效地处理大规模数据集,并被广泛应用于数据挖掘、搜索引擎、自然语言处理、机器学习、图像处理等领域,以下是MapReduce的优势和产品优势的详细分析。
MapReduce 技术优势
1、并行处理能力:
MapReduce允许数据并行处理,通过将大规模数据集分成小块,同时在多个计算节点上执行操作,显著提高了数据处理速度和效率。
2、高容错性:
在集群中的节点失败时,MapReduce框架会自动重新执行失败的任务,确保任务的完成,从而具有很高的容错性。
3、易于扩展:
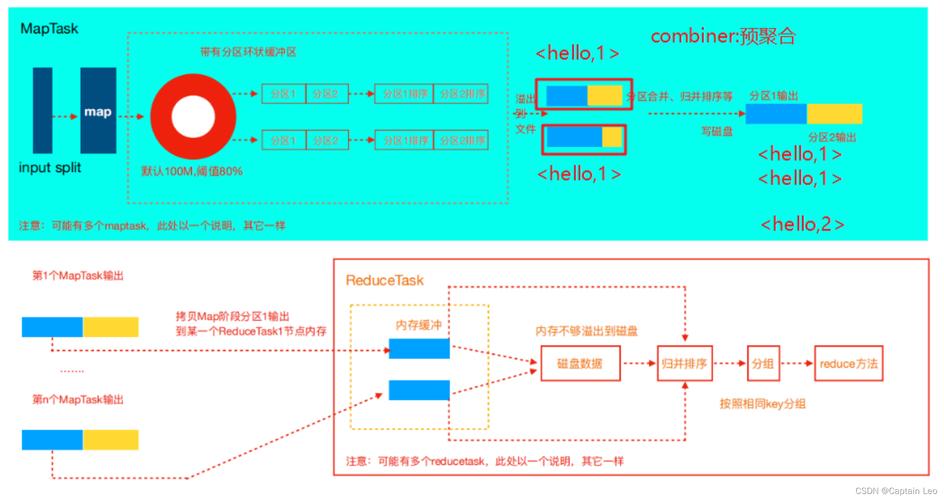
MapReduce可以轻松地扩展到更多的计算节点,以处理更多数据,这使其非常适合应对不断增长的数据量。
4、通用性:
MapReduce是一种通用的数据处理模型,适用于各种领域,包括大规模数据分析、搜索引擎索引构建、日志分析、机器学习等。
5、数据局部性优化:
支持数据局部性,即将数据分配给附近的计算节点,以减少数据传输的开销,从而提高性能。
6、简化的编程模型:
开发人员只需要实现Map和Reduce函数,而不需要关心并行和分布式计算的细节,这大大简化了编程过程。
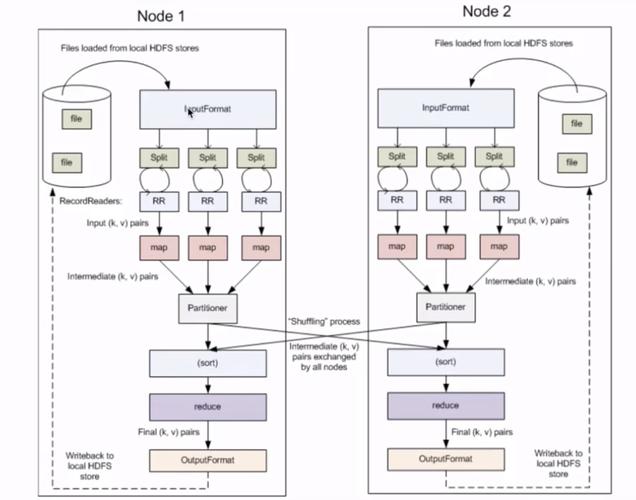
7、自动排序和分组:
自动处理键的排序和分组,确保相同键的数据被发送到相同的Reduce任务,使得分组和聚合操作更容易实现。
8、适合处理大规模数据:
作为处理大规模数据的有效工具,MapReduce可以应对数千亿条记录和大型数据集。
9、合理的数据流设计:
提供了一个合理的数据流,使开发人员能够逐步处理数据,从而使复杂的任务分解成简单的步骤。
MapReduce 产品优势
1、易用性:
用户可以选择所需的ECS机型(CPU、内存)与磁盘,并进行自动化部署,简化了集群的搭建和管理。
2、灵活性:
用户可以按需创建集群,即离线作业运行结束就可以释放集群,还可以在需要时动态地增加节点。
3、深度整合:
与阿里云其他产品如对象存储服务(OSS)、消息队列服务(MNS)、云数据库(RDS)等深度整合,使其可作为Hadoop/Spark计算引擎的输入源或者输出目的地。
4、安全性:
整合了阿里云RAM资源权限管理系统,通过主子账号对服务权限进行隔离,保障数据安全。
5、高性能:
MRS支持自研的CarbonData存储技术,以一份数据同时支持多种应用场景,提升了IO扫描和计算性能。
6、低成本:
基于多样化的云基础设施,提供了丰富的计算、存储设施的选择,同时计算存储分离,提供了低成本海量数据存储方案。
7、高安全性:
MRS服务拥有企业级的大数据多租户权限管理能力,支持数据按照表/按列加密,确保数据安全。
8、易运维:
提供可视化大数据集群管理平台,提高运维效率,并支持滚动补丁升级,无需人工干预,保障用户集群长期稳定。
9、高可靠性:
经过大规模的可靠性、长稳验证,满足企业级高可靠要求,同时支持数据跨AZ/跨Region自动备份的数据容灾能力。
相关问答FAQs
Q1: MapReduce 适合处理哪些类型的任务?
A1: MapReduce 适合处理大规模数据集的任务,包括但不限于数据分析、搜索引擎索引构建、日志分析、机器学习等领域,它的并行处理能力和高容错性使其成为处理这些任务的理想选择。
Q2: 使用 MapReduce 有哪些成本效益?
A2: 使用 MapReduce 可以带来显著的成本效益,它允许按需创建和释放集群,节省了资源闲置时的成本,通过计算存储分离,提供了低成本海量数据存储方案,MapReduce 的自动伸缩能力可以根据业务需求动态调整资源,进一步降低了成本。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/844453.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复