


MapReduce 统计样例程序
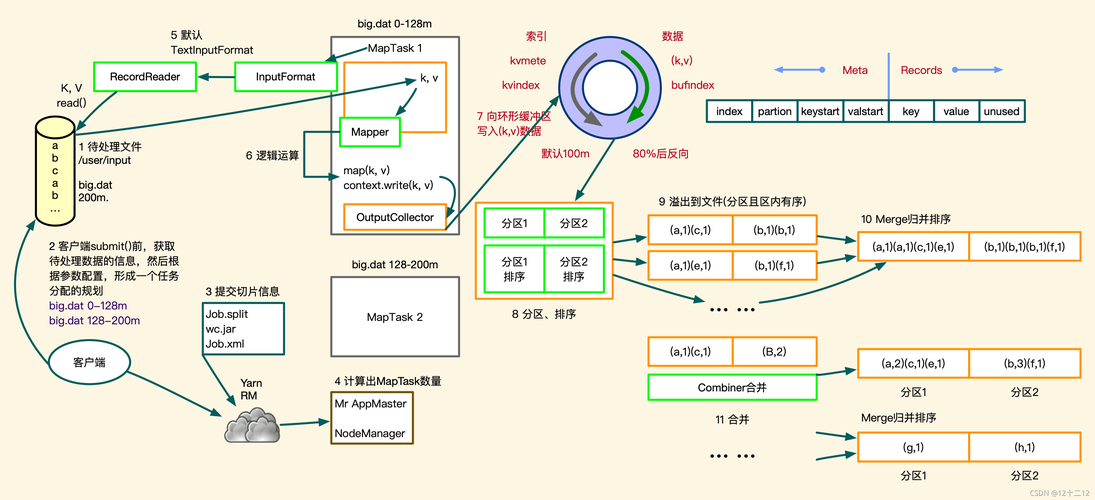

MapReduce是一种分布式运算编程框架,用于大规模数据集的处理,下面通过一个简单的实例来解析MapReduce的工作流程和基本原理。
1. MapReduce基本概念
MapReduce主要由两个阶段组成:Map阶段和Reduce阶段,这两个阶段分别对应Map函数和Reduce函数,它们处理的数据以键值对的形式存在,Map函数负责处理输入数据并生成一系列中间键值对;而Reduce函数则负责对这些中间键值对进行汇总处理,以生成最终的输出结果。
2. MapReduce实例 单词统计
假设需要统计一段文本中每个单词出现的次数,这个任务非常适合用MapReduce来处理。
Map阶段:这一阶段的任务是把输入文本拆分成单词,并为每个单词计数,Map函数会遍历输入文本的每一行,用空格或其他分隔符将每行拆分成单词,并为每个单词生成一个<key, value>对,key是单词本身,value是该单词出现的次数(初始为1),对于文本 "hello world hello",Map阶段的输出可能是 <"hello", 1>, <"world", 1>, <"hello", 1>。
Shuffle and Sort阶段:这是连接Map和Reduce的中间阶段,由MapReduce框架自动完成,它的主要任务是对Map阶段的输出进行排序和分组,在这个例子中,相同的键(即单词)会被归类到一起,形成<key, list(value)>对,对于上述输入,shuffle and sort阶段的输出将是 <"hello", [1, 1]>, <"world", [1]>。
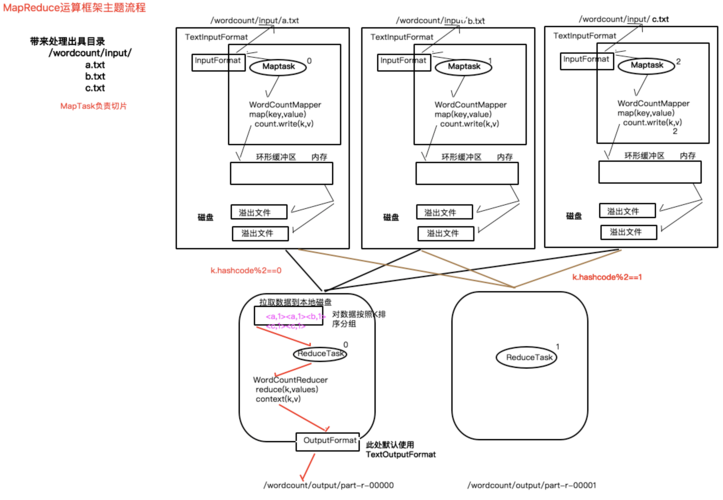
Reduce阶段:Reduce阶段的任务是对相同键的所有值进行汇总处理,在这个例子中,Reduce函数将遍历values列表,并将所有值累加起来,得到每个单词的总出现次数,最终的输出结果是 <"hello", 2>, <"world", 1>。
3. MapReduce核心组件
在MapReduce的工作流程中,涉及到以下四个核心组件:
Client:用户编写的MapReduce程序通过Client提交到JobTracker端,并且可以通过Client查看作业运行状态。
JobTracker:负责资源监控和作业调度,JobTracker监控所有TaskTracker与Job的健康状况,并在发现失败时将任务转移到其他节点,JobTracker跟踪任务的执行进度和资源使用情况,并通知给任务调度器。
TaskTracker:在集群的每个节点上运行,周期性地向JobTracker报告本节点的资源使用情况和任务运行进度,它还接收JobTracker的命令执行相应的操作,如启动新任务或杀死任务。
Task:分为Map Task和Reduce Task两种,均由TaskTracker启动,Map Task负责处理输入数据,并生成中间结果;Reduce Task则负责处理这些中间结果,并生成最终的输出文件。
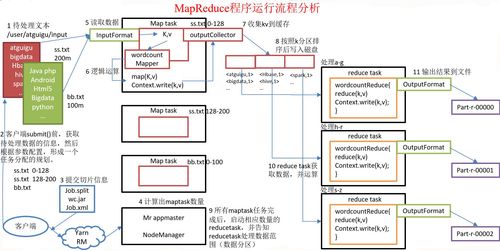
4. MapReduce执行流程
以单词统计为例,MapReduce的具体执行流程如下:
作业提交:用户通过Client将编写好的MapReduce作业(如单词统计程序)提交到Hadoop集群。
作业初始化:JobTracker接收到作业请求后,将其加入作业队列进行初始化操作,这一过程包括创建作业对象、配置作业信息、生成输入分片等。
任务分配和执行:JobTracker根据输入数据的位置信息和当前集群的工作负载情况,选择合适的TaskTracker来执行Map任务和Reduce任务,Map任务通常在数据所在的节点上执行以优化数据传输效率。
Map任务执行:Map Task开始执行,首先读取split中的数据(例如文本文件的一部分),然后逐行交给Mapper处理,Mapper处理逻辑是用户自定义的,例如拆分行中的单词并计数,处理完成后,生成的键值对暂存于内存中。
Shuffle and Sort阶段:这是一个过渡阶段,MapReduce框架会自动对Map的输出进行排序和分组,确保同一Key的所有值被送到同一个Reducer。
Reduce任务执行:Reduce Task开始执行,其任务是将Map阶段的输出作为输入,遍历所有的<key, list(value)>对,并对每个key对应的value列表进行汇总处理,例如求和,最终生成<key, result>形式的输出。
结果输出:Reduce任务处理完后,将最终结果输出到HDFS文件中,至此,整个MapReduce作业执行完成,用户可以在HDFS上查看和验证结果。
5. MapReduce优缺点分析
MapReduce虽然功能强大且易编程,但同样存在一些局限性:
优点:易于编程,只需实现几个接口即可完成大规模分布式程序;良好的扩展性,通过增加机器就能轻松扩展计算能力;高容错性,设计初衷就是部署在廉价PC上,具备高容错性;适合PB级以上海量数据的离线处理。
缺点:不擅长实时计算,无法像MySQL那样快速返回结果;不擅长流式计算,因为输入数据集必须是静态的;不擅长DAG计算,多个应用程序存在依赖关系时性能低下。
相关问答FAQs
Q1: MapReduce适用于哪些场景?
MapReduce非常适合于大规模数据集的离线处理,例如大文本数据的分析和统计、大规模日志数据的处理、机器学习中的数据挖掘等,由于其简单的编程模型和强大的分布式处理能力,MapReduce能够有效解决海量数据处理的难题。
Q2: 如何优化MapReduce的性能?
优化MapReduce性能可以从以下几个方面入手:合理设置Map和Reduce的数量,确保每个Map Task处理的数据量均匀分布;优化数据输入格式和输出格式,减少不必要的数据传输和磁盘IO;合理设置内存缓冲区大小,避免频繁的磁盘写入操作;选择合适的压缩方式,减少网络传输的数据量;优化Mapper和Reducer的业务逻辑代码,提高代码执行效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/844324.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复