


MapReduce的压缩输入配置和Parquet表的压缩格式是两个不同的概念,但它们都涉及到数据压缩以提高存储和处理效率,下面分别介绍这两个概念:

MapReduce的压缩输入配置
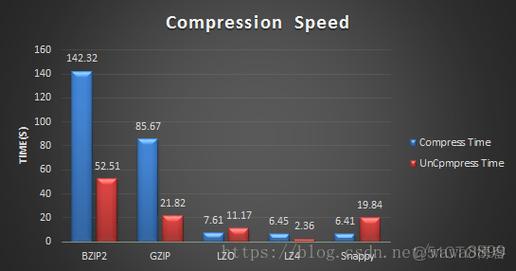
在Hadoop MapReduce中,可以通过配置输入数据的压缩格式来减少磁盘I/O操作和网络传输的数据量,常见的压缩格式有:
gzip
bzip2
LZO
Snappy
LZ4
要在MapReduce作业中配置输入数据的压缩格式,可以在mapreduce.job.inputformat.class属性中指定一个支持压缩的输入格式类,例如org.apache.hadoop.mapreduce.lib.input.TextInputFormat,在mapreduce.job.inputformat.compress.codec属性中设置所需的压缩编解码器。
示例:使用gzip压缩格式
<configuration>
<property>
<name>mapreduce.job.inputformat.class</name>
<value>org.apache.hadoop.mapreduce.lib.input.TextInputFormat</value>
</property>
<property>
<name>mapreduce.job.inputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.GzipCodec</value>
</property>
</configuration> Parquet表的压缩格式
Apache Parquet是一种列式存储格式,它可以高效地存储和查询大量结构化数据,Parquet文件支持多种压缩编码方案,包括:
GZIP
Snappy
LZO
Brotli (从Parquet 1.9.0开始支持)
Uncompressed
要在创建Parquet表时配置压缩格式,可以使用以下方法之一:
1、在创建表时使用STORED AS PARQUET子句并指定压缩编解码器,
“`sql
CREATE TABLE my_table (col1 INT, col2 STRING) STORED AS PARQUET TBLPROPERTIES (‘parquet.compression’=’SNAPPY’);
“`
2、在写入Parquet文件时,使用适当的API参数设置压缩编解码器,例如在Java中使用ParquetWriter:
“`java
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
// …
CompressionCodecName codec = CompressionCodecName.SNAPPY;
ParquetWriter<MyRecord> writer = new ParquetWriter<>(new Path("output.parquet"), MyRecord.getSchema(), codec);
“`
注意:Parquet文件的压缩和解压缩操作是在读取或写入数据时进行的,而不是在创建表时,选择适当的压缩格式取决于您的具体需求,如存储空间、查询性能和计算资源。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/844091.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复