


关于MapReduce函数原理,以下是详细的解析:
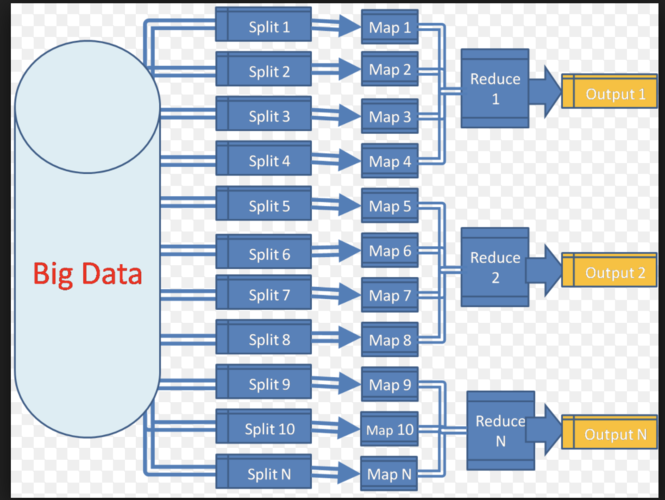

1、MapReduce的基本概念
定义与目的:MapReduce是一个编程模型,用于大规模数据集的并行运算,它通过将计算任务分解为两个主要阶段——Map和Reduce,来处理和生成大数据集。
核心组件:包括Mapper、Reducer、Shuffle和Sort等部分,每个组件负责处理特定的任务阶段。
2、Map阶段的详解
数据的输入与处理:Map阶段接收输入数据,并将其分割成多个键值对,这些键值对被提供给Mapper进行处理。
Mapper的作用:Mapper函数把输入数据转换成一系列的中间键值对,这些中间键值对是Map阶段的直接输出,通常不会保存在稳定存储中,而是直接传输到下一阶段。
3、Shuffle和Sort阶段
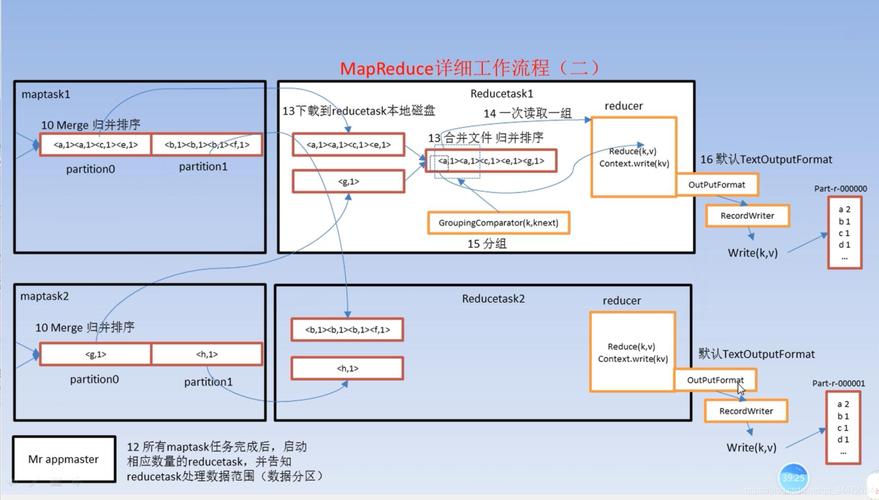
数据分组与排序:这一阶段主要是对Map阶段的输出进行排序和分组,确保相同键的数据被组织在一起,准备传递给Reducer。
数据传输:经过排序和分组的数据需要通过网络传输到执行Reduce任务的节点上。
4、Reduce阶段的详解
数据的汇总与输出:Reduce阶段接收来自Shuffle和Sort阶段的输出,对这些中间键值对使用Reducer函数进行处理,生成最终的输出结果。
Reducer的任务:Reducer的工作是对具有相同键的所有值进行聚合处理,例如计算总和、平均值或其他汇总操作。
5、非循环数据流的优势
可靠性与性能优化:采用从稳定存储到稳定存储的非循环数据流模式可以减少数据处理中的复杂性,提高系统的可靠性和性能。
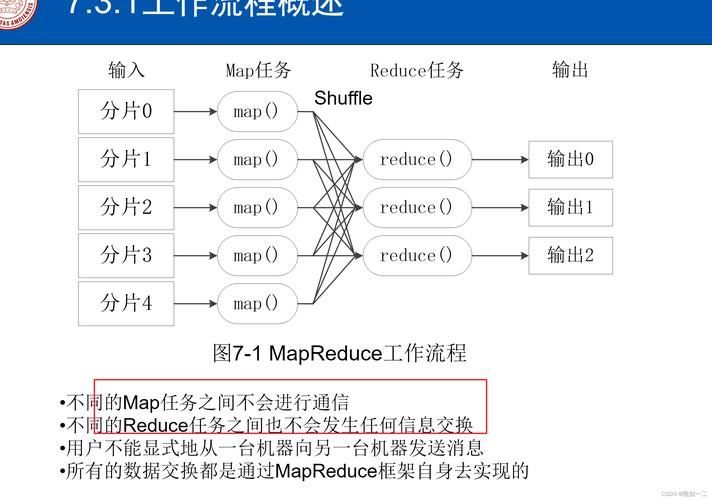
6、MapReduce的成本问题与优化
磁盘与HDFS的使用:由于频繁的磁盘IO操作和大规模的数据传输,MapReduce可能会面临高昂的处理成本,优化措施包括内存计算、增加节点和资源、以及数据压缩和合并技术的应用。
在使用MapReduce进行数据处理时,需要注意以下几点:
尽量优化数据结构和算法以减少不必要的计算和数据传输。
利用合适的数据分区和分组策略,以确保数据均匀分配到各个Reducer,避免某些节点成为瓶颈。
考虑在适当的情况下使用数据压缩技术,以减少在网络中传输的数据量。
实施适当的错误处理和数据验证机制,确保数据的完整性和准确性。
MapReduce是一种强大的分布式计算框架,专门设计用于处理大规模数据集,通过理解其基本工作原理和关键技术组件,可以有效地设计和优化数据处理任务,以应对各种复杂的数据分析需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/843922.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复