


关于MapReduce中的序列化,尤其是在数据序列化方面,是确保数据能够在分布式系统中有效传输和处理的关键技术,下面将详细介绍MapReduce中的数据序列化:
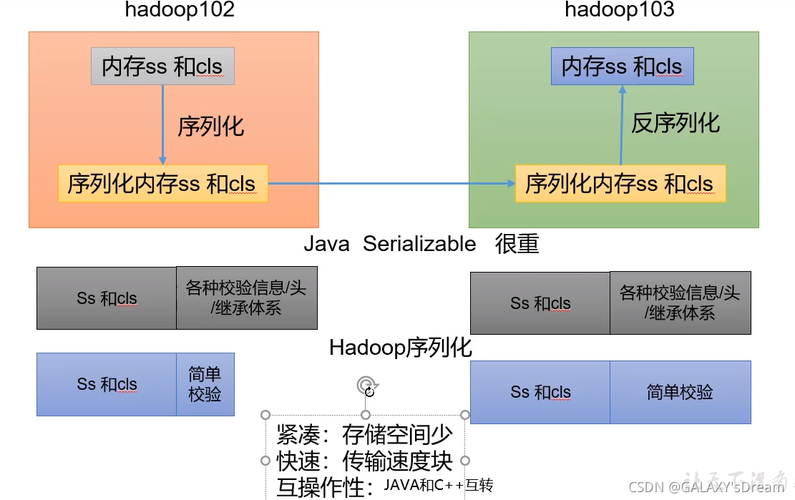

1、序列化
什么是序列化:序列化是将内存中的对象状态转换为可以存储或传输的字节序列的过程,反序列化则是将这些字节序列还原为内存中对象的过程。
Java序列化与Hadoop序列化的对比:Java自带的序列化机制(使用Serializable接口)相较于Hadoop自定义的序列化机制(使用Writable接口)更为重量级,会附带更多额外信息,不利于网络高效传输,Hadoop开发了更为紧凑和快速的序列化框架。
自定义对象的序列化实现套路:为了在Hadoop中使用自定义对象,需要实现Writable接口,并重写write和readFields方法以进行序列化和反序列化操作,同时确保有空参数的构造函数,以便在反序列化时通过反射创建对象实例。
2、Hadoop序列化特点
紧凑:Hadoop的序列化机制设计得更为紧凑,能够更高效地使用存储空间。
快速:读写数据的额外开销小,提高了数据处理速度。
互操作性:支持多语言交互,使得不同编程语言之间能够更容易地进行数据交换。
可扩展性:随着通信协议的升级而可升级,保证了技术的前瞻性。
3、实现Hadoop的Writable接口
基本步骤:要实现Writable接口,自定义类需要提供无参数构造器,重写write方法实现序列化过程,以及重写readFields方法实现反序列化过程。
Hadoop的基本序列化类型:Hadoop提供了一些基本的序列化类型,如IntWritable、Text等,但对于更复杂的数据类型,需要自行实现Writable接口。
4、序列化案例实操
需求分析:统计每个手机号耗费的总上行流量、总下行流量及总流量的需求,涉及到自定义对象的序列化处理。
自定义Bean对象:创建一个实现了Writable接口的流量统计Bean对象FlowBean,注意保持序列化和反序列化的顺序完全一致。
编写Mapper、Reducer和Driver:编写对应的Mapper、Reducer组件以及Driver程序来读取、处理和输出数据。
测试:最后进行测试验证,确保整个流程的正确性和效率。
MapReduce中的数据序列化是处理大规模数据集时不可或缺的一个环节,通过有效的序列化机制,如Hadoop的Writable接口,可以显著提高数据处理的效率和网络传输的性能,在实际应用中,根据具体需求设计和实现自定义的序列化方案是非常关键的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/843563.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复