


MapReduce
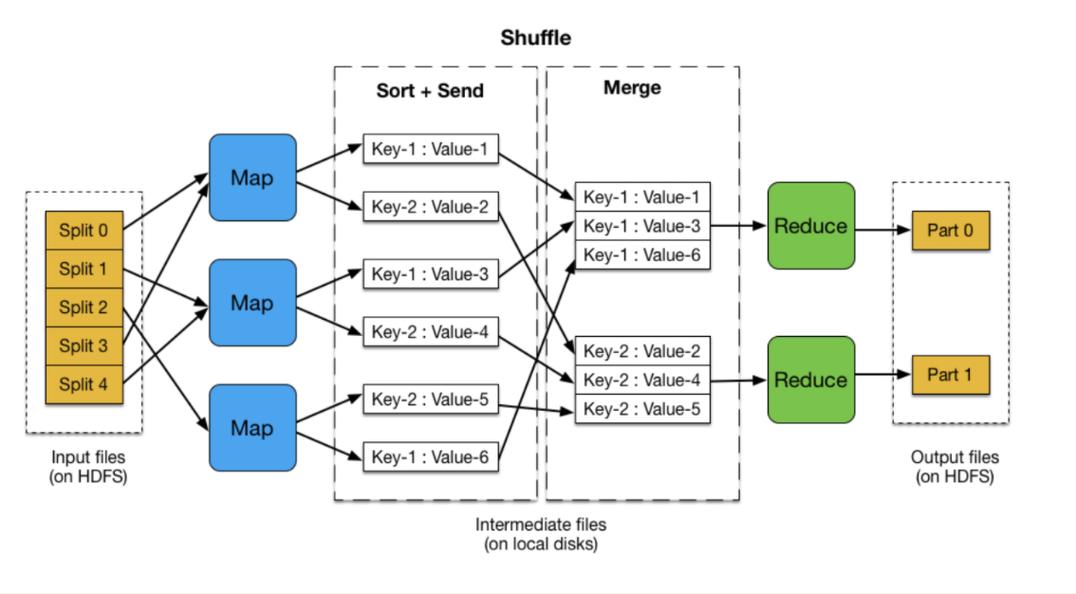

MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它最早由Google提出,旨在解决大规模数据的并行处理问题,MapReduce的核心是将任务分为两个阶段:Map阶段和Reduce阶段,在Map阶段,数据被分解成一系列键值对,交由各个Mapper处理;而在Reduce阶段,具有相同键的键值对被聚合在一起,并由Reducer进行处理以生成最终结果,这种模型极大地简化了大规模并行计算的编程难度,使得开发人员能够在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
MapReduce体系结构与工作流程
MapReduce体系结构主要由四个部分组成:Client、JobTracker、TaskTracker和Task,用户通过Client提交MapReduce程序到JobTracker端,并可通过Client查看作业运行状态,JobTracker负责资源监控和作业调度,而TaskTracker则负责具体任务的执行,并周期性地将节点上的资源使用情况和任务运行进度汇报给JobTracker。
在一个典型的MapReduce工作流程中,输入数据从分布式文件系统(如HDFS)中并行读取,经过Map和Reduce处理,最终结果被写入到分布式文件系统中,Map阶段负责将输入数据集分解成键值对,并传递给Mapper函数进行处理;Shuffle阶段则将这些键值对按键进行排序和分组,准备传递给Reducer;在Reduce阶段,具有相同键的键值对被合并,并将结果输出。
MapReduce的优缺点
优点
1、易于编程:MapReduce提供了简单的编程模型,开发者只需实现Map和Reduce两个主要函数即可构建分布式应用程序。
2、良好的扩展性:可以通过简单地增加机器来扩展计算能力,适合构建在廉价PC上的大规模集群。
3、高容错性:设计初衷是使程序能够部署在廉价PC上,具有很高的容错性,一个节点失败不会影响整个作业。
缺点
1、不擅长实时计算:MapReduce无法像传统数据库那样快速返回结果。
2、不擅长流式计算:输入数据必须是静态的,不能动态变化,不适合流式数据处理。
3、不擅长DAG计算:多个存在依赖关系的应用程序会降低性能。
相关FAQs
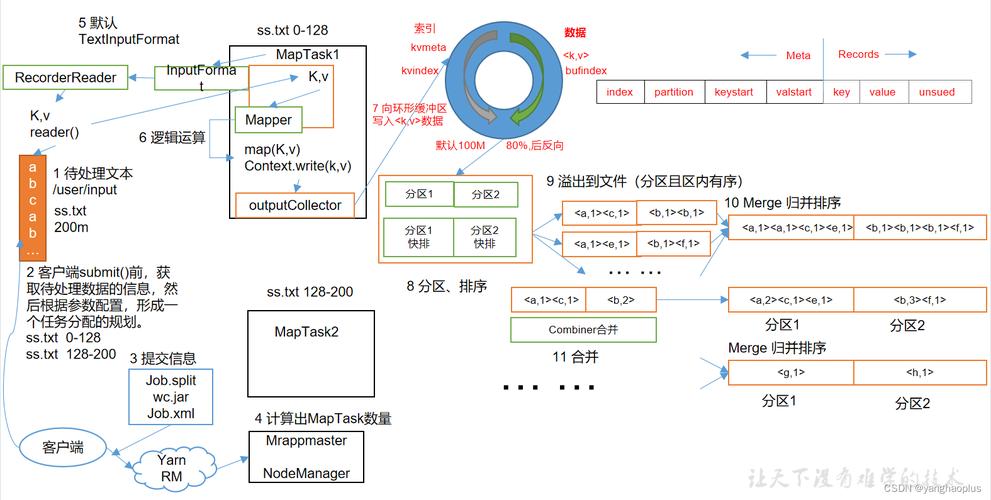
1. MapReduce中的Shuffle阶段是如何工作的?
Shuffle阶段是MapReduce框架中的一个重要环节,它负责将Map阶段的输出传输到Reduce阶段作为输入,首先根据键值对的键进行分区,然后将具有相同键的数据分组并排序,最后将这些数据分发到对应的Reducer上,这个过程涉及到大量的磁盘IO和网络传输,因此优化Shuffle阶段的效率对提高MapReduce作业的整体性能至关重要。
2. 如何优化MapReduce的性能?
优化MapReduce性能可以从以下几个方面入手:
1、减少Shuffle数据传输量:可以通过压缩中间数据或使用Combiner来减少数据传输量。
2、合理设置Map和Reduce的数量:根据集群的实际能力和作业需求调整Map和Reduce任务的数量,以达到最优的资源利用。
3、优化数据存储格式:使用高效的数据存储格式可以减少数据读写的开销,提高作业执行效率。
归纳而言,MapReduce作为一种强大的分布式计算框架,通过简化编程模型,使得开发者能够轻松地处理大规模数据集,尽管存在一定的局限性,但其高度的可扩展性和容错能力使其成为大数据分析的重要工具,通过合理优化,MapReduce能够高效地满足各种复杂数据处理需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/843247.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复