


关于MapReduce中的关联(join)操作,以下是详细的解释和分析:
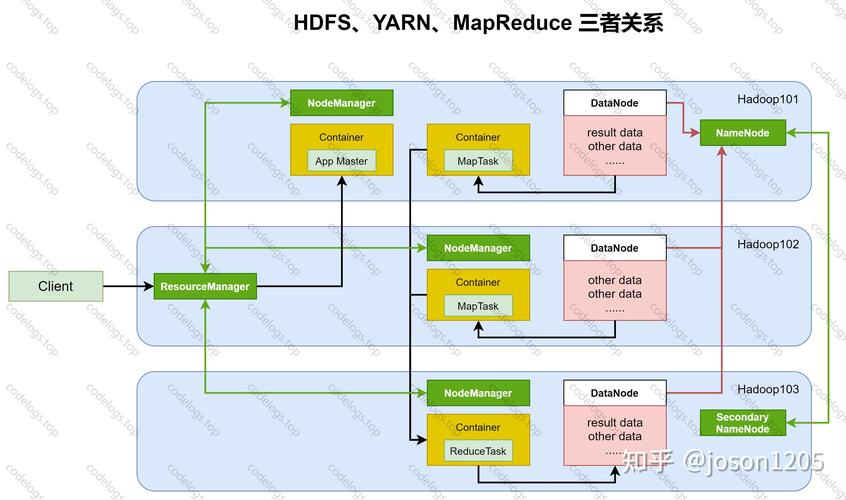

MapReduce是一种编程模型,用于处理大规模数据集,它将计算过程分为两个主要阶段:Map阶段和Reduce阶段,在MapReduce中实现关联操作是处理大数据集上的常见需求,尤其是在数据分散存储的环境下。
MapReduce关联类型
1、Reduce Side Join
原理:在Reduce阶段执行关联操作。
步骤:Mapper分别读取不同的数据集;以连接字段作为输出的key;相同key的数据经shuffle过程分到同一分组;Reducer进行数据关联整合汇总。
案例:通过订单表和商品表的goodsId字段关联,得到每笔订单的具体商品名称信息。
弊端:所有数据挤压到Reduce阶段处理,压力大;shuffle成本高。
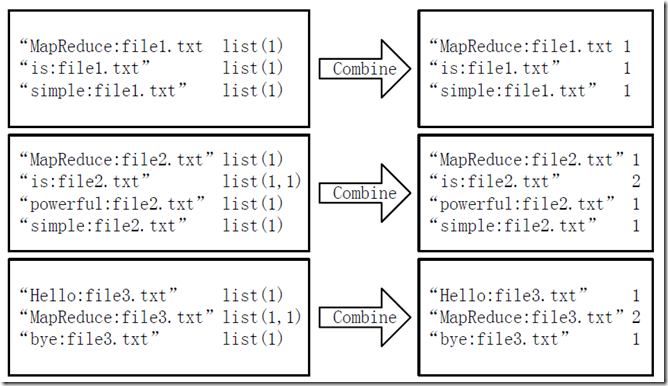
2、Map Side Join
原理:在Map阶段执行关联操作,避免了Reduce阶段的处理。
步骤:使用分布式缓存技术将小数据集缓存;Map阶段从缓存中读取小数据集并与大数据集关联;无需Reduce阶段,直接输出结果。
优势:减少数据传输成本;充分发挥mapper并行度的优势。
3、DistributedCache优化
作用:缓存应用程序所需文件,提高作业效率。
使用方式:添加缓存文件;在Mapper或Reducer的setup方法中读取缓存文件。
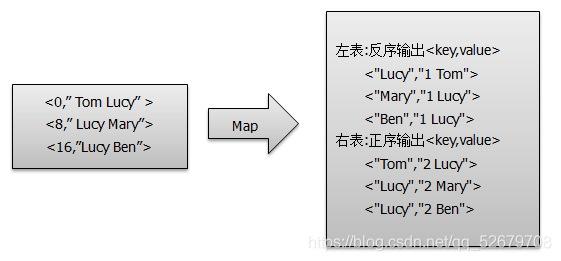
具体案例
Reduce Side Join案例
1、需求:统计每笔订单中对应的具体商品名称信息。
2、数据结构:
order: id, date, pid, amount
product: pid, pname, category_id, price
3、实现步骤:
分别读取order和product表数据。
根据订单商品的pid作为key进行数据输出。
在Reduce阶段根据来源文件标记合并关联字段相同的数据。
Map Side Join案例
1、需求:在仅有一个大数据集和一个小数据集的场景下,避免Reduce阶段的繁琐操作。
2、实现步骤:
使用DistributedCache缓存小数据集。
在Map阶段读取缓存的小数据集并与大数据集进行关联。
直接输出最终结果,无需Reduce阶段。
归纳与对比
Reduce Side Join适合大小相近的数据集关联,但存在性能瓶颈。
Map Side Join适合“一大一小”数据集场景,优势在于减少了数据传输成本,提高了效率。
注意事项
确保数据已存储在HDFS中,Hive表的结构已经定义好。
针对不同数据集格式,Map阶段需判断并区别处理。
合理设置Reduce并行度以平衡性能和输出结果分散性。
利用DistributedCache优化小数据集的处理,提升作业效率。
通过上述详细解析,可以了解到MapReduce中关联操作的基本原理、实现方式以及适用场景,在实际工作中,可以根据数据规模和具体需求选择合适的方法进行关联操作,以达到最优的性能表现。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/843123.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复