


大数据基础知识
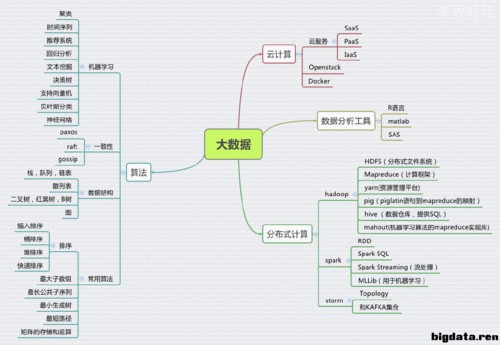

数据分片和路由
在大数据的背景下,数据规模已经由GB级别跨越到PB甚至EB级别,单机无法存储与处理如此规模的数据量,必须依靠大规模集群来对这些数据进行存储和处理,对于海量的数据,通过数据分片(Shard/Partition)将数据切分到不同机器中去,分片后,如何快速找到某一条记录,这就是数据的分片和路由技术所要解决的问题。
数据复制与一致性
在大数据的存储系统中,为了增加系统的可靠性,通常会将同一份数据存储多个副本,这就引入了数据复制的问题,同时带来数据一致性的挑战,数据复制的方式有多种,如主从复制、多主复制等,解决数据一致性的方法包括两阶段提交、分布式事务等。
数据采集技术框架
数据采集是大数据生命周期的第一个环节,涉及结构化、半结构化和非结构化数据,常见的数据采集方式包括系统日志采集、网络数据采集和设备数据采集,Flume、Logstash和FileBeat常用于日志数据实时监控采集;Sqoop和DataX常用于关系型数据库离线数据采集;Canal和Maxwell常用于关系型数据库实时数据采集。
数据传输技术框架
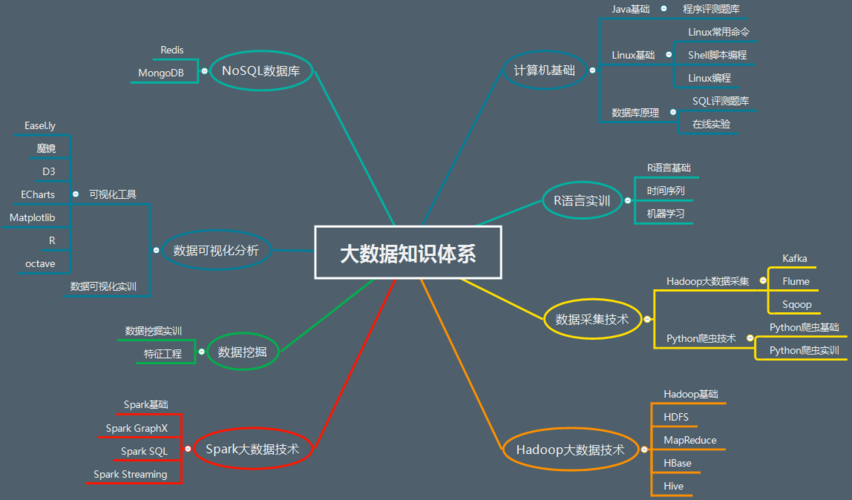
经过采集的数据需要通过数据通道传输存储,数据传输的技术包括消息队列、数据同步、数据订阅和序列化,Kafka作为一个高吞吐量的分布式消息系统,常用于缓冲海量数据;数据同步则解决各个数据源之间稳定高效的同步功能;序列化将对象转换为可存储或传输的形式,对大数据传输的性能有直接影响。
大数据存储与计算
数据存储技术框架
大数据存储面向海量、异构、非结构化等数据提供高性能、高可靠的存储及访问能力,存储方案包括物理存储和分布式文件/对象存储系统,HDFS解决了海量数据存储问题,但不支持单条数据修改操作;HBase是一个基于HDFS的NoSQL数据库,支持数据修改;Kudu则介于两者之间,既支持数据修改也支持基于SQL的数据分析。
分布式资源管理框架
随着大数据时代的到来,临时任务的需求量大增,这些任务往往需要大量的服务器资源,传统的人工对接资源变更已不现实,因此出现了分布式资源管理系统,如YARN、Kubernetes和Mesos,它们提供了灵活的资源调度和管理功能,保证系统高效运行。
数据计算技术框架
数据计算分为离线数据计算和实时数据计算,离线计算方面,MapReduce是第一代离线数据计算引擎,Spark通过内存计算极大提高了性能;实时计算方面,Storm、Flink和Spark Streaming分别在不同场景下提供实时数据处理能力。
数据分析与任务调度
数据分析技术框架
数据分析技术框架包括Hive、Impala、Kylin等离线OLAP分析引擎,以及Clickhouse、Druid等实时OLAP分析引擎,这些工具在不同场景下提供高效的数据分析能力,例如Hive适合高稳定性需求的场景,Impala适合高性能需求的场景。
任务调度技术框架
任务调度技术框架包括Azkaban、Oozie、DolphinScheduler等,适用于普通定时执行任务及包含复杂依赖关系的多级任务调度,支持分布式,保证调度系统的性能和稳定性。
大数据底层基础与检索技术
大数据底层基础技术框架
Zookeeper是大数据底层基础技术的核心组件,主要提供命名空间、配置服务等功能,Hadoop HA、HBase、Kafka等组件都依赖于Zookeeper来实现分布式协同和一致性保障。
数据检索技术框架
针对海量数据的快速复杂查询需求,全文检索引擎工具如Elasticsearch、Solr、OpenSearch等提供了易用性、扩展性、稳定性等方面的不同选择,这些检索工具不仅支持多样化的查询需求,还能实现高效的数据分析和搜索功能。
归纳与展望
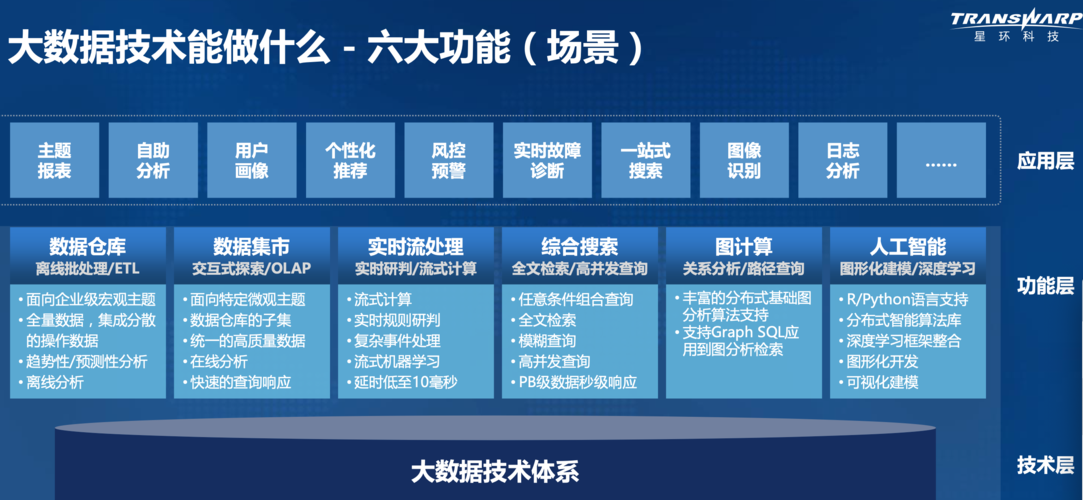
大数据技术涵盖了从数据采集、传输、存储、计算到分析、调度等多方面的内容,每一个环节都有其重要性,随着技术的发展,大数据生态圈不断完善,新的技术和工具不断涌现,大数据将继续深入到各个领域中,发挥其巨大的价值和潜力,为企业和社会创造更多的机遇和可能性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/842653.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复