


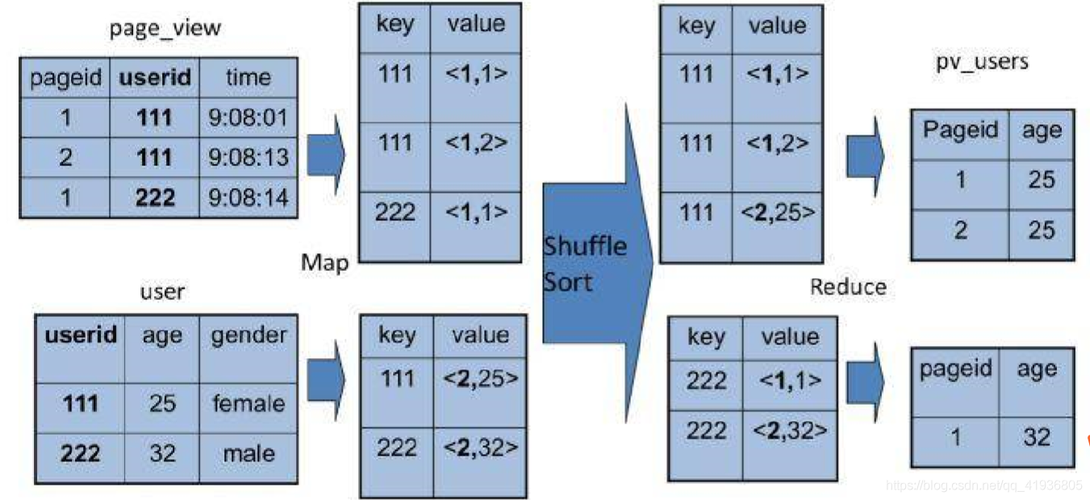
MapReduce是一种编程模型,用于处理和生成大数据集的并行计算,在MapReduce中,数据被分成多个独立的块,每个块在不同的节点上进行处理,排序是MapReduce中的一个常见操作,它可以按照键(key)或值(value)进行排序。


如果你想要按照键(key)对MapReduce的结果进行排序,可以使用Hadoop的内置排序功能,以下是一个简单的示例:
1、创建一个MapReduce作业,定义Mapper和Reducer类。
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; public class KeySortingJob { public static class KeySortingMapper extends Mapper<LongWritable, Text, IntWritable, Text> { private final static IntWritable one = new IntWritable(1); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split("\s+"); for (String word : words) { context.write(new IntWritable(word.length()), new Text(word)); } } } public static class KeySortingReducer extends Reducer<IntWritable, Text, IntWritable, Text> { public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { context.write(key, value); } } } }
2、配置作业并运行它,在这个例子中,我们使用IntWritable作为键类型,Text作为值类型,Mapper将输入文本分割成单词,并为每个单词生成一个键值对,其中键是单词的长度,值是单词本身,Reducer将所有具有相同长度的单词组合在一起。
3、为了按键(key)对结果进行排序,我们需要在作业配置中设置mapreduce.job.output.key.comparator.class属性,Hadoop提供了一些内置的比较器,例如org.apache.hadoop.mapreduce.lib.partition.KeyFieldBasedComparator,可以用于按键排序。
<configuration>
<property>
<name>mapreduce.job.output.key.comparator.class</name>
<value>org.apache.hadoop.mapreduce.lib.partition.KeyFieldBasedComparator</value>
</property>
<property>
<name>mapreduce.partition.keycomparator.options</name>
<value>k1,1</value>
</property>
</configuration> 4、运行作业并查看输出结果,输出文件将按照键(key)进行排序。
注意:这个示例仅适用于按键(key)排序的情况,如果你需要按照列(column)排序,你需要在Reducer阶段实现自定义排序逻辑,或者在MapReduce之外使用其他数据处理工具,如Pandas或Spark。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/840460.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复