


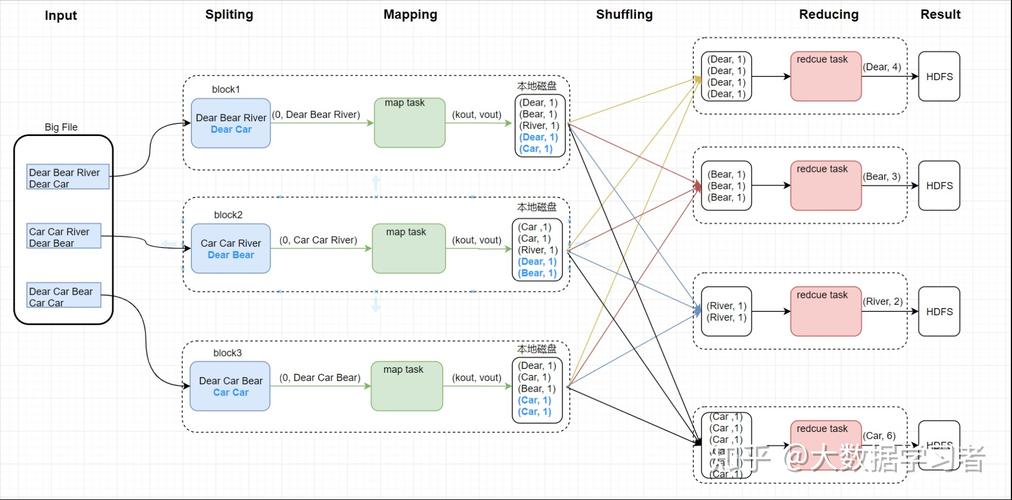
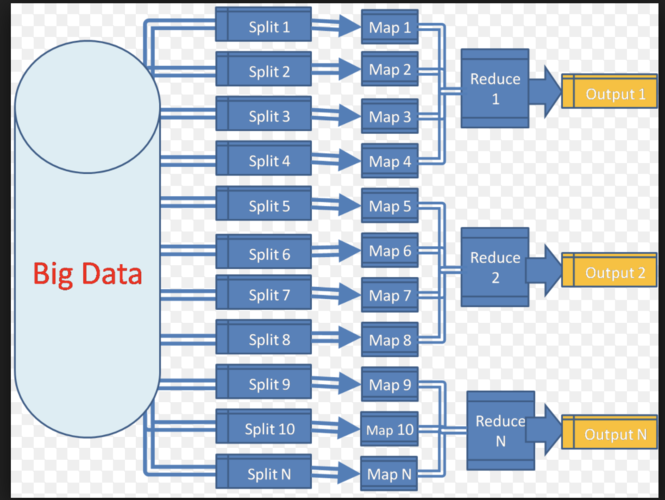
关于MapReduce任务长时间无进展的问题,下面将详细分析其原因及解决方案:

1、内存资源不足
任务配置优化:适当增加堆内存空间可以减少任务拷贝map输出的时间,从而减少等待时间,根据mapper的数量和各mapper的数据大小来优化任务配置是必要的。
参数调整示例:如果10个mapper的数据大小为5GB,那么理想的堆内存是1.5GB,随着数据大小的增加而增加堆内存大小。
2、数据倾斜问题
可能性分析:在出现任务长时间卡死的现象时,应首先考虑数据倾斜问题,通过检查YARN控制台的作业信息可以判断是否为数据倾斜,如果有大量的reduce任务长时间运行,而非少部分,则可能不是数据倾斜所致。
排除倾斜:对MR程序处理的源数据文件进行按Key值分组计算,如果没有数据分布不均衡的情况,则可以排除因数据倾斜导致作业卡死的可能性。
3、Hadoop集群组件状态
状态分析:通过查看Hadoop集群UI页面上各组件状态以及系统服务日志信息,可以确认集群及各组件是否运行正常,从而排除因集群本身问题导致作业卡死的可能性。
4、日志分析
异常作业容器信息:分析异常作业容器信息、失败map任务日志、失败reduce任务日志、长时间卡死的reduce任务的syslog日志等,可以帮助找到任务卡死的原因。
核心原因发现:通过查看长时间卡死的reduce任务的进程栈信息,可能发现reduce任务获取map任务完成事件的线程状态是阻塞,即reduce任务在等待map任务完成的信号但一直没收到,这可能是导致作业卡死的原因。
5、Yarn资源分配问题
资源分配过程:一个Job被提交后需要经历资源分配的过程,这通常需要数秒钟的时间,如果过长,可能是Yarn资源分配过程遇到了问题。
Yarn配置检查:仔细检查yarnsite.xml文件的配置,确保没有标点错误或字母打错等问题。
6、磁盘健康检查机制
磁盘使用率问题:如果节点的某几块磁盘达到高使用率,可能会因为yarn的磁盘健康检查机制导致任务失败,需要确保有足够的健康磁盘来避免任务失败的情况。
7、MapReduce配置优化
合理设置Task数量:Map和Reduce的数量都不能设置太少,也不能设置太多,太少会导致task等待,延长处理时间;太多则可能导致任务间竞争资源,造成处理超时等错误。
规避使用Reduce:Reduce在用于连接数据集的时候将会产生大量的网络消耗,合理规避使用可以减少网络IO的时间。
为了进一步优化MapReduce任务的执行效率,还可以考虑以下几点:
数据处理优化:在执行MR任务前,合并小文件可以减少map任务装载次数,解决输入端大量小文件场景的问题。
Map阶段优化:通过调整相关参数值,增大触发spill的内存上限,减少spill次数,从而减少磁盘 IO。
Reduce阶段优化:合理设置map和reduce共存,减少reduce的等待时间。
IO传输优化:采用数据压缩的方式,减少网络IO的时间,安装Snappy和LZOP压缩编码器。
MapReduce任务长时间无进展的问题可能由多种因素引起,包括内存资源不足、数据倾斜、集群组件状态不正常、日志分析中的异常、Yarn资源分配问题、磁盘健康检查机制以及MapReduce配置优化等方面,通过逐一排查和调整这些因素,可以有效解决任务长时间无进展的问题,还可以通过数据处理优化、Map阶段优化、Reduce阶段优化和IO传输优化等措施进一步提升MapReduce任务的执行效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/839881.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复