

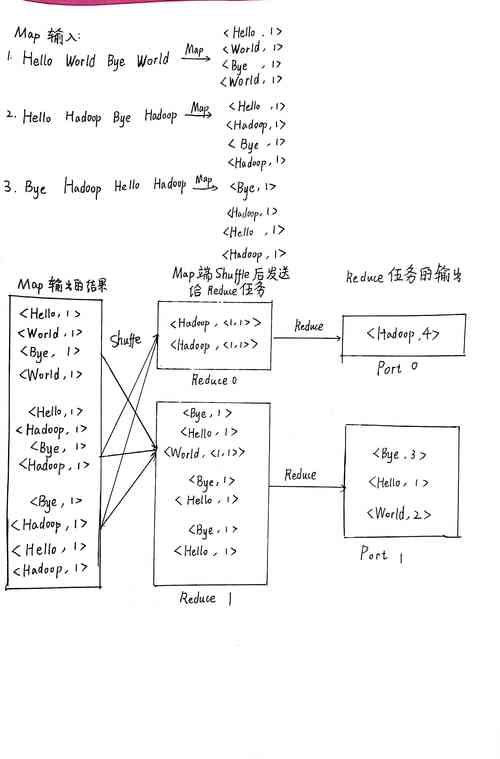
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个阶段组成:Map阶段和Reduce阶段,在统计记录数的场景中,我们可以使用MapReduce来计算输入数据集中的总记录数。
(图片来源网络,侵删)
以下是一个MapReduce统计记录数的样例代码:
from mrjob.job import MRJob
class MRCountRecords(MRJob):
def mapper(self, _, line):
# 输出键值对,键为固定字符串'count',值为1
yield 'count', 1
def reducer(self, key, values):
# 对于每个键(这里是'count'),计算其对应的值的总和
total = sum(values)
yield key, total
if __name__ == '__main__':
MRCountRecords.run() 代码解释:
1、导入mrjob.job模块中的MRJob类。
2、定义一个名为MRCountRecords的类,继承自MRJob。
3、在MRCountRecords类中定义mapper方法,该方法接收两个参数:一个是键(在这里我们不关心键,所以用下划线表示),另一个是行数据,对于每一行数据,我们输出一个键值对,键为固定字符串’count’,值为1,这样,我们就可以在后续的Reduce阶段对所有值为1的键进行计数。
4、定义reducer方法,该方法接收两个参数:一个是键,另一个是该键对应的所有值的列表,在这个例子中,我们只有一个键’count’,所以我们只需要计算这个键对应的值的总和,即记录数。
5、在__main__部分,运行MRCountRecords类的run方法来启动MapReduce作业。

(图片来源网络,侵删)
要运行此代码,你需要安装mrjob库,并将上述代码保存为count_records.py文件,你可以在命令行中使用以下命令运行MapReduce作业:
python count_records.py input_file.txt
其中input_file.txt是包含你要统计记录数的数据的文件,执行完毕后,你将在控制台看到输出的结果,显示总记录数。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/839617.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复