


mapreduce 容错
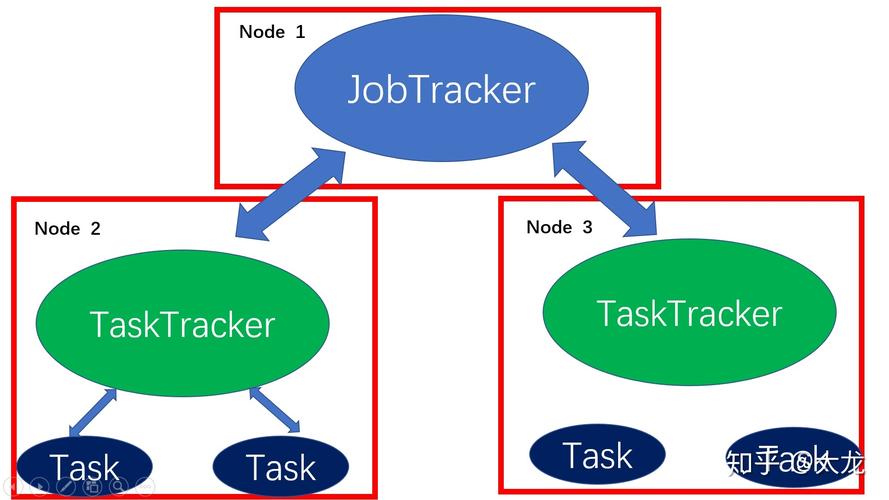

MapReduce是用于大规模数据处理的编程模型,它通过将任务分配到多个节点上并行处理来提高计算速度和可靠性,在分布式环境中,节点故障是一个常见问题,因此容错机制对于确保作业顺利完成至关重要,本文将探讨MapReduce中的容错机制,包括任务失败的处理、数据备份以及系统恢复等方面。
任务失败处理
MapReduce框架通过监控各个任务的执行状态来检测失败,如果一个任务失败了,框架会自动重新调度该任务到其他节点上执行,这种重试机制可以应对暂时性的硬件或网络问题,而不会导致整个作业失败。
Map任务失败
当一个Map任务失败时,正在运行的Reduce任务不会受到影响,因为Map和Reduce阶段是独立的,失败的Map任务会被重新安排到另一个节点上执行,同时已经完成的Map输出仍然有效,可以被后续的Reduce任务使用。
Reduce任务失败
Reduce任务的失败处理与Map任务类似,失败的Reduce任务会被重新安排到其他节点,Reduce任务依赖于所有Map任务的输出,因此在Reduce任务失败的情况下,需要确保所有必要的Map输出都可用。
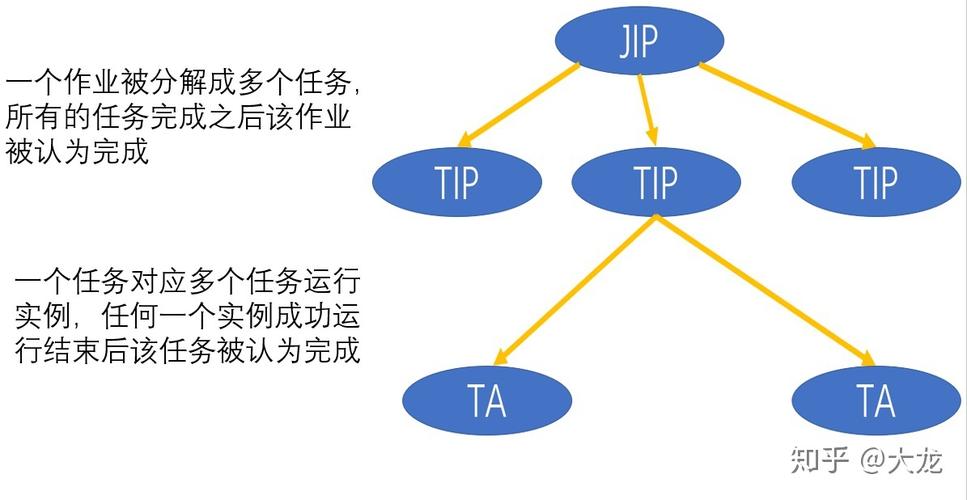
为了进一步提高容错能力,MapReduce框架通常会对数据进行备份,这包括输入数据的分割副本和Map输出的备份。
输入数据备份
输入数据通常会被分成多个数据块,每个数据块有多个副本分布在不同的节点上,这样即使某个节点发生故障,其他节点上的副本仍然可用,保证了数据的可靠性。
Map输出备份
Map任务的输出也会被复制到多个节点上,以便Reduce任务可以从任何副本中获取所需的数据,这种冗余确保了即使某些副本不可用,Reduce任务也能继续执行。
系统恢复
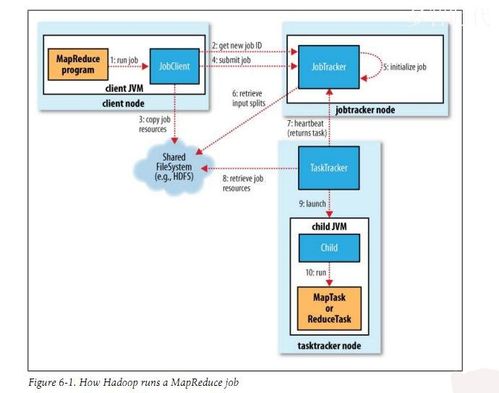
在MapReduce作业执行过程中,可能会遇到整个节点甚至集群级别的故障,在这种情况下,系统的恢复机制就显得尤为重要。
节点级恢复
如果一个节点发生故障,该节点上的任务会被迁移到其他健康的节点上执行,系统会从其他节点上的副本中恢复丢失的数据,以保证作业的连续性。
集群级恢复
在更严重的情况下,如整个集群出现故障,可能需要从备份中恢复数据和服务,这通常涉及到将数据从备份存储恢复到新的硬件上,并重新启动MapReduce服务。
性能考虑
虽然容错机制提高了系统的可靠性,但同时也带来了额外的开销,数据备份会增加存储成本,任务重试会增加计算资源的消耗,在设计MapReduce作业时,需要权衡性能和容错性,以达到最优的系统配置。
相关问答FAQs
Q1: MapReduce中的容错机制是否会影响作业的性能?
A1: 是的,容错机制确实会对性能产生影响,数据备份会增加存储成本,任务重试会增加计算资源的消耗,这些开销是为了确保作业在面对硬件故障或网络问题时能够顺利完成,在设计作业时,需要在性能和容错性之间做出权衡。
Q2: 如果一个Map任务失败了,已经运行的Reduce任务会怎样?
A2: 如果一个Map任务失败了,正在运行的Reduce任务不会受到影响,失败的Map任务会被重新安排到其他节点上执行,而已经完成的Map输出仍然有效,可以被后续的Reduce任务使用,这是因为Map和Reduce阶段是独立的,Reduce任务可以处理任何可用的Map输出。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/839249.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复