


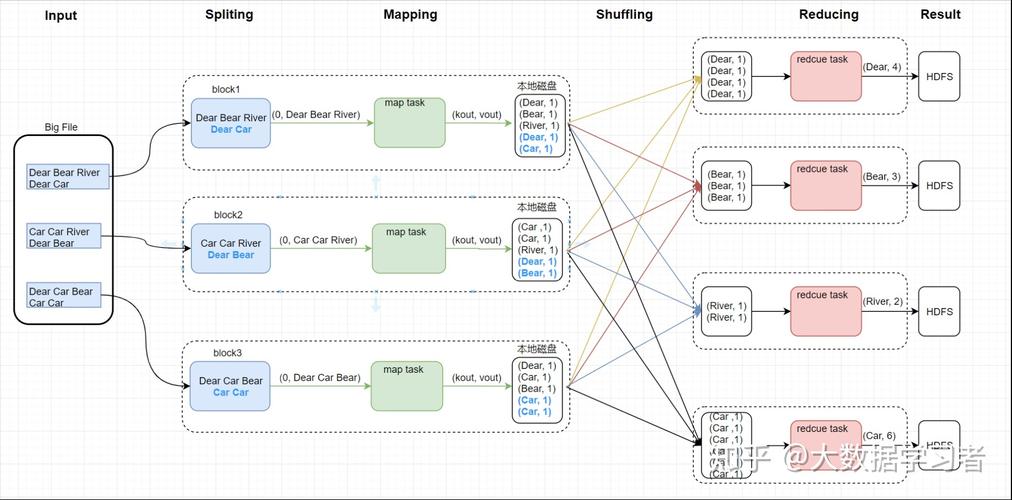
MapReduce程序实例展示了如何使用MapReduce框架进行数据统计。它通常包括一个映射(Map)阶段,用于将输入数据转换为键值对;和一个归约(Reduce)阶段,用于汇总具有相同键的值。统计文本中单词的出现频率。
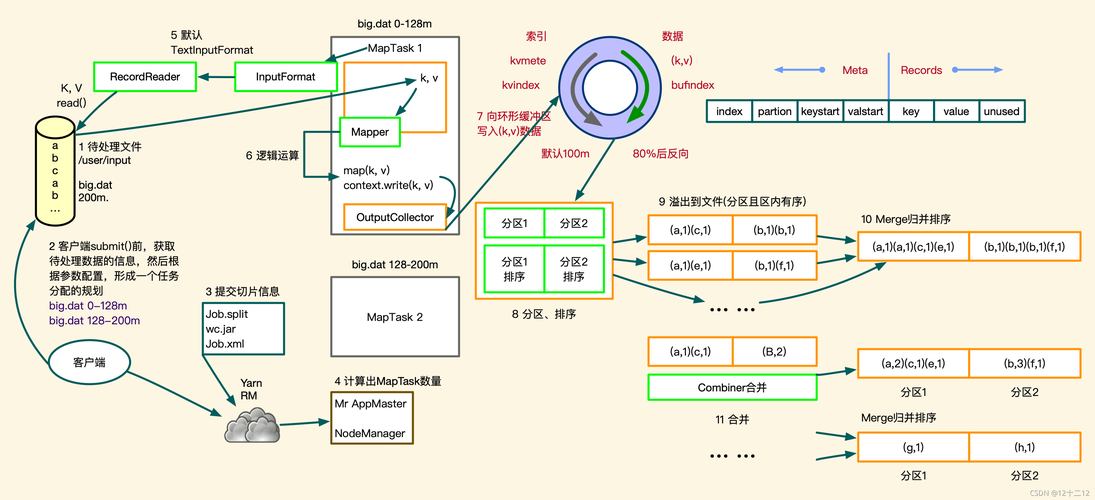
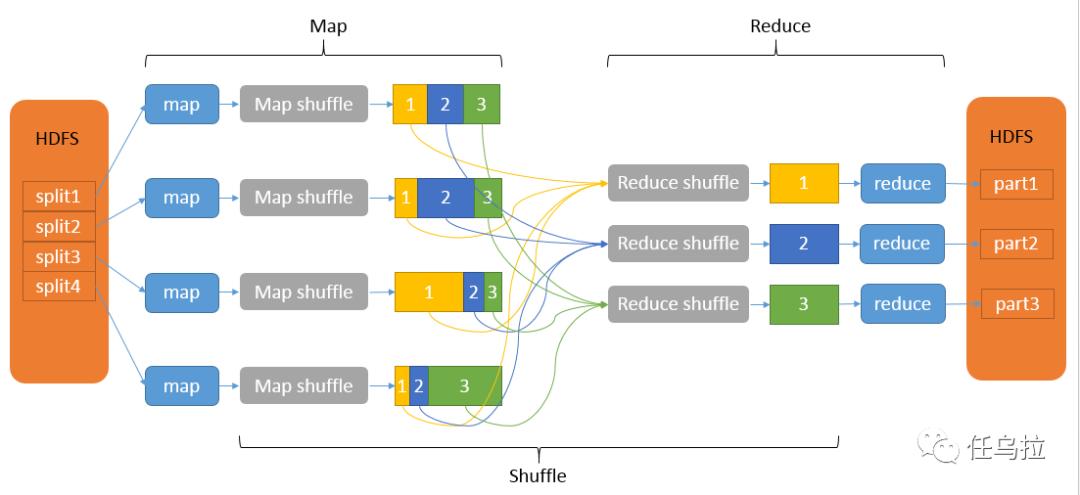
MapReduce是一种编程模型,用于处理和生成大数据集,它包括两个主要阶段:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个小块,然后每个小块由一个Map任务进行处理,在Reduce阶段,所有Map任务的输出被合并成一个最终的结果。

(图片来源网络,侵删)
下面是一个使用Java编写的简单的MapReduce程序,用于统计文本中每个单词出现的次数。
1. Map阶段
在Map阶段,我们的任务是将输入的文本分割成单词,并为每个单词生成一个键值对,其中键是单词,值是1。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} 2. Reduce阶段
在Reduce阶段,我们的任务是将具有相同键(即相同的单词)的所有值(即出现次数)相加,以得到每个单词的总出现次数。
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} 3. 主程序
我们需要一个主程序来配置和启动MapReduce作业。
(图片来源网络,侵删)
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 这个程序将从命令行参数指定的输入路径读取文本文件,然后将单词计数的结果写入到指定的输出路径。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/839166.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复