


MapReduce与MySQL中的JOIN操作对比及实现

在大数据和传统数据库处理中,数据连接(JOIN)是一种常见且重要的操作,本文将详细探讨在MapReduce框架下实现JOIN操作的方法,并与传统的MySQL JOIN进行对比。
MapReduce中的JOIN操作
在Hadoop的MapReduce编程模型中,数据的处理分为两个主要阶段:Map阶段和Reduce阶段,这种分布式计算框架为处理大规模数据集提供了强大的支持,但在实现数据间的关联(JOIN)操作时,其方法与传统的关系型数据库有所不同。
Reduce Side Join
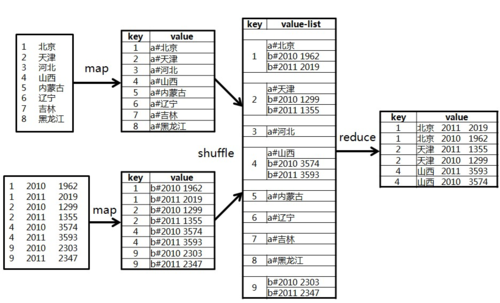
最常见的MapReduce JOIN实现是Reduce Side Join,在这种模式下,Mapper读取来自不同数据集的记录,并以连接字段作为key输出,经过MapReduce的shuffle阶段,所有具有相同key的记录会被发送到同一个Reducer,这样,Reducer便可以在一个统一的节点上对相关数据进行合并处理。
具体步骤包括:
1、Mapper读取数据:分别处理不同数据集中的记录,以连接字段作为key,记录来源等信息作为value。
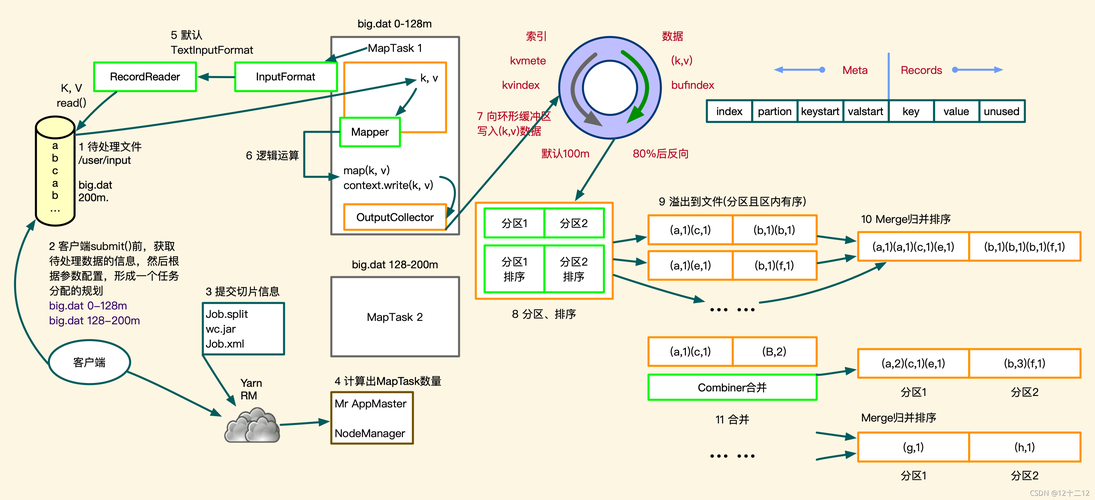
2、Shuffle和Sort:自动过程,确保相同key的记录被传送到同一个Reducer。
3、Reducer执行JOIN:根据业务逻辑合并来自不同数据集的记录,并输出最终结果。
弊端:
由于大多数工作在Reduce阶段完成,Reducer的数量限制(默认为1)可能导致性能瓶颈。
Shuffle过程在处理大量数据时效率较低,增加了额外的开销。
为了解决Reduce Side Join的问题,Map Side Join提供了一个优化方案。
Map Side Join
Map Side Join适用于一大一小的数据集场景,通过将小数据集分布式缓存到各个Map节点,直接在Map阶段完成连接操作,避免了shuffle的复杂性。
实现步骤:
1、使用DistributedCache:将小数据集文件分发到各个Map任务节点。
2、Map Task执行时加载小数据集:在Mapper的setup方法中,从分布式缓存读取小数据集并存储在内存中(如Hash表)。
3、执行JOIN操作:Map任务处理大数据集时,直接查找内存中的小数据集进行JOIN操作,并输出结果。
优势:
减少了网络传输,降低了shuffle的复杂度。
能够更好地利用Map阶段的并行计算能力。
MySQL中的JOIN操作
在传统的关系型数据库(如MySQL)中,JOIN操作通常通过SQL语句实现,数据库系统内部优化器会根据表结构、索引和查询条件选择最优的执行计划。
实现方式
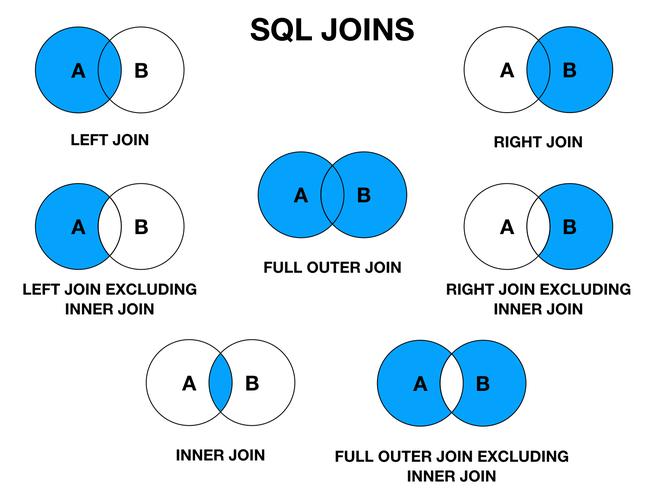
INNER JOIN:只返回两个表中匹配的行。
LEFT/RIGHT JOIN:返回一个表中的所有行,及其在另一个表中匹配的行;未匹配的行以NULL填充。
FULL OUTER JOIN:返回两个表中的所有行,匹配的行被合并。
MySQL的JOIN操作高度优化,利用索引和表统计信息来加速查询,数据库管理员可以调整索引策略以进一步提升性能。
MapReduce vs. MySQL JOIN性能比较
| 特性 | MapReduce | MySQL |
| 并行处理 | 高度并行 | 单线程至并行包处理 |
| 优化器 | 无 | 有高效的优化器 |
| 索引 | 无 | 有 |
| JOIN类型 | 需要手动实现 | 自动支持多种类型 |
| 数据规模 | 适合超大规模数据 | 适合中等规模数据 |
| 性能瓶颈 | Shuffle和Reducer限制 | 索引和查询优化 |
| 易用性 | 编程要求较高 | SQL语言简洁明了 |
MapReduce JOIN案例分析
以订单商品处理为例,假设有两份数据文件:itheima_goods(商品信息表)和itheima_order_goods(订单信息表),目标是统计每笔订单对应的具体商品名称信息。
Reduce Side 实现步骤:
1、Mapper阶段:分别处理商品数据和订单数据,以goodsId作为key输出,可以通过FileSplit获取文件名,区分不同数据源。
2、Reducer阶段:同一goodsId的商品和订单信息被分组到同一个Reducer,进行关联合并,输出最终结果。
Map Side 实现步骤:
若其中一份数据集相对较小,例如itheima_goods,则可以采用Map Side Join:
1、使用DistributedCache:将itheima_goods文件分发到各Map节点。
2、Map Task:在Mapper初始化时加载缓存数据,处理itheima_order_goods数据时直接进行JOIN操作。
3、输出结果:Map阶段完成后即可得到最终结果文件。
相关问答FAQs
1、问:MapReduce中的Reduce Side Join和Map Side Join有何优劣?
答:Reduce Side Join容易实现但效率较低,因为大部分处理在Reduce阶段完成,shuffle过程繁琐且可能成为性能瓶颈,而Map Side Join适用于一大一小数据集的场景,优势在于减少了网络传输和shuffle开销,充分利用了Map阶段的并行计算能力。
2、问:如何选择合适的JOIN策略(MapReduce vs. MySQL)?
答:对于超大规模数据处理,尤其是非结构化或半结构化数据,MapReduce更加适合,它能够提供高度并行的处理能力,而对于结构化数据和复杂关联查询,MySQL凭借其成熟的优化器和丰富的索引机制,通常能提供更高效、易用的方案,在选择时需考虑数据规模、处理速度要求、易用性和开发成本等因素。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/838332.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复