


网站间相互访问的基本概念
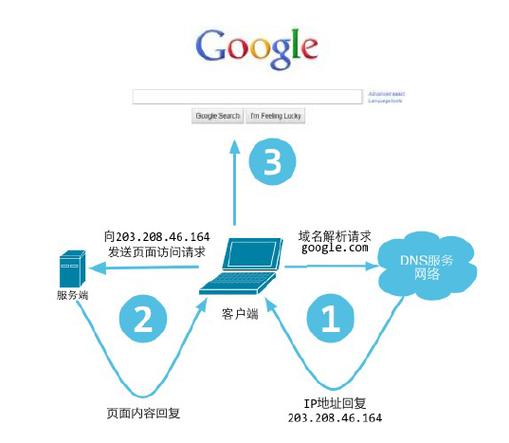

在互联网的世界中,网站之间的相互访问是日常操作的一部分,这种访问可以是用户直接通过浏览器从一个网站跳转到另一个网站,也可以是网站后端通过API(应用程序编程接口)调用、Web爬虫或其他自动化方式进行的数据交换和信息获取。
用户层面的网站访问
用户通常通过点击超链接、输入网址或使用搜索引擎来访问网站,当用户在一个网站上点击指向另一个网站的链接时,他们的浏览器会向目标网站的服务器发送一个请求,然后服务器响应这个请求并将网页内容返回给用户的浏览器,最终呈现给用户。
浏览器工作原理
1、DNS解析:将域名转换为IP地址。
2、建立TCP连接:确保数据安全传输。
3、发送HTTP请求:浏览器对服务器的资源发起请求。
4、服务器响应:服务器返回请求的资源。
5、浏览器渲染页面:解析HTML、CSS和JavaScript等,展示页面。
服务器层面的网站访问
在后端,服务器间的通信往往涉及到数据的交换和处理,这可以通过以下几种方式实现:
API调用
RESTful API:一种基于HTTP协议的软件架构风格,用于前后端分离的应用中。
SOAP API:一种基于XML的消息传递协议,用于网络服务中。

Web爬虫
自动抓取网页内容的机器人程序,常用于搜索引擎索引、在线价格监控等。
数据交换格式
JSON:轻量级的数据交换格式。
XML:标记语言,用于存储和传输数据。
安全性考虑
在进行网站间的相互访问时,安全性是一个不可忽视的问题,攻击者可能会利用跨站脚本攻击(XSS)、SQL注入、跨站请求伪造(CSRF)等手段来窃取信息或破坏系统,为了防范这些风险,网站需要采取相应的安全措施,如:
使用HTTPS加密通信。
对用户输入进行验证和清理,防止注入攻击。
实施内容安全策略(CSP),限制外部资源的加载。
使用验证码或Token来防止自动化攻击和CSRF。
法律和隐私问题
网站间的访问还涉及到法律法规和用户隐私的问题,欧盟的通用数据保护条例(GDPR)要求企业在处理个人数据时必须遵守特定的规则,网站在设计跨站访问功能时,必须考虑到这些法律法规的要求,并确保用户的隐私得到保护。
性能优化
为了提高用户体验,网站间的相互访问需要考虑性能优化,这包括减少HTTP请求次数、使用CDN(内容分发网络)来缓存静态资源、压缩文件大小、优化图片和选择合适的加载策略等。
相关问答FAQs
Q1: 如何检查我的网站是否被其他网站引用?
A1: 你可以使用谷歌的“link:”搜索运算符来查看哪些网站链接到了你的网站,只需在谷歌搜索栏中输入“link:你的网站URL”,就可以得到一个列表,还可以使用专门的反向链接分析工具,如Ahrefs、SEMrush等,它们能提供更详细的数据分析。
Q2: 我的网站应该如何防止恶意爬取?
A2: 为了防止恶意爬取,你可以采取以下措施:
设置Robots.txt文件来指导爬虫的行为。
在网站后台实施访问频率限制,对频繁请求的IP进行封禁。
使用验证码或人机识别技术来区分正常用户和爬虫程序。
监测服务器日志,分析异常流量模式并及时响应。
加强网站的安全措施,如使用防火墙和入侵检测系统。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/837705.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复