


DISTINCT关键字实现。如果你有一个名为students的表,并且你想要查询所有不重复的名字,你可以执行以下SQL语句:,,“sql,SELECT DISTINCT name FROM students;,`,,这将返回一个结果集,其中包含students`表中所有不重复的名字。在MySQL数据库中,处理重复数据是一项常见的需求,尤其是在进行数据分析、报表生成或数据清洗时,本文将详细介绍在MySQL中如何消除重复的列,特别是针对PI(可能指主索引Primary Index或其他特定字段)的重复消除方法,我们将通过多种技术和查询示例,全面解析这一过程。
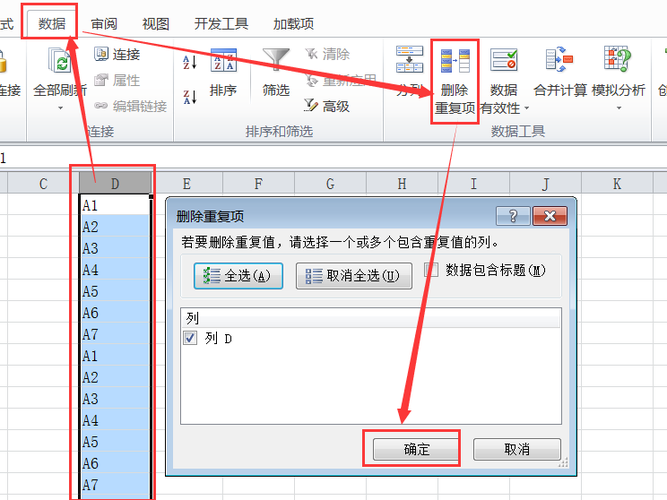

使用DISTINCT去除重复数据
最基本的去重方法是使用SELECT DISTINCT语句,此方法适用于简单的单列或多列去重,如果你有一个包含重复email地址的用户表,可以使用如下查询去除重复的email:
SELECT DISTINCT email FROM users;
这条查询将返回所有不重复的email列表,但这种方法仅适用于返回唯一值,而不是实际删除表中的重复行。
使用GROUP BY分组去重
GROUP BY语句可以与聚合函数结合使用来去重,并且它允许你选择保留哪个数据行,如果你希望基于用户的名字和姓氏去重,同时保留每个用户的最小ID,可以这样操作:
SELECT first_name, last_name, MIN(id) as min_id FROM users GROUP BY first_name, last_name;
这会为每个具有相同名字和姓氏的用户组返回一条记录,并显示最小的ID。
利用INNER JOIN删除重复行
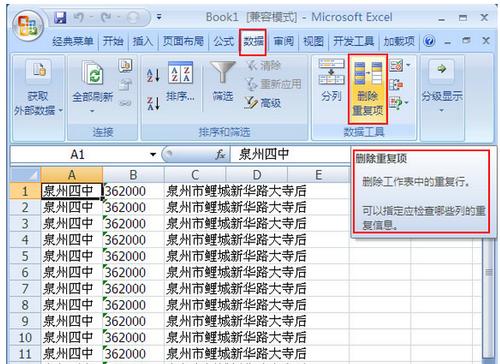
当需要从表中实际删除重复行时,可以使用INNER JOIN,这种方法特别适用于有唯一标识符(如ID)的情况,以下是一个示例,展示了如何删除重复的email行,同时保留具有最低ID的行:
DELETE t1 FROM users t1 INNER JOIN users t2 WHERE t1.id > t2.id AND t1.email = t2.email;
这个查询将删除email相同的较高ID的行。
使用ROW_NUMBER()函数去重
在MySQL 8.0.2及更高版本中,可以使用ROW_NUMBER()窗口函数来为结果集中的每一行分配一个唯一的数字,这对于更复杂的去重需求非常有用,比如当你想基于多个条件对数据进行排序并选择特定行时,以下是一个例子:
WITH RankedUsers AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY email ORDER BY id) as row_num
FROM users
)
DELETE FROM RankedUsers WHERE row_num > 1; 这个例子中,我们首先创建一个名为RankedUsers的CTE(公共表表达式),其中包含一个由ROW_NUMBER()生成的额外列,我们删除所有row_num大于1的行,从而只保留每个email地址的最低ID行。
相关问答FAQs
Q1: 如何在不删除原表数据的情况下创建一个无重复数据的新表?
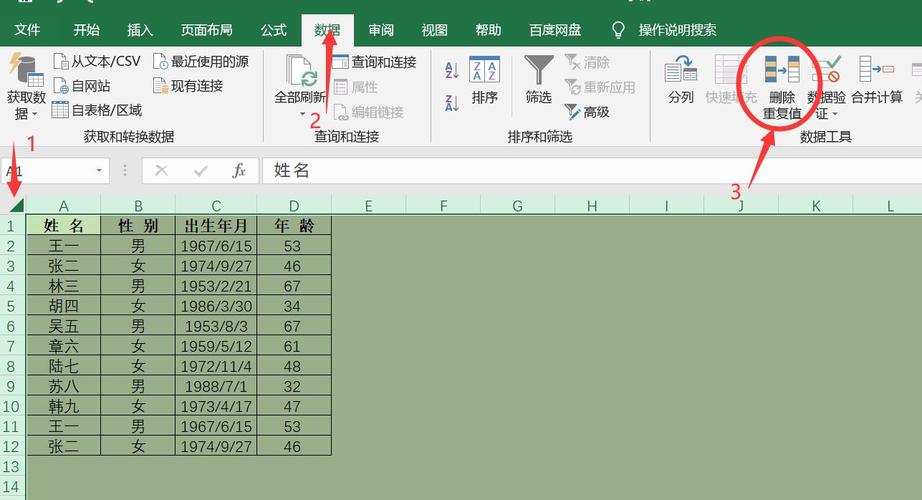
A1: 你可以创建一个新表,然后将去重后的数据插入到这个新表中,使用以下SQL语句:
CREATE TABLE deduplicated_users AS SELECT DISTINCT * FROM users;
或者,使用GROUP BY和适当的聚合函数来选择你想要保留的特定行。
Q2: 在使用ROW_NUMBER()函数去重时有哪些注意事项?
A2: 使用ROW_NUMBER()时,你需要确保正确设置PARTITION BY和ORDER BY子句,以准确地定义如何对数据进行分组和排序,由于ROW_NUMBER()是一个窗口函数,它只在MySQL 8.0.2及更高版本中可用,确保你的数据库版本支持此功能。
方法提供了在MySQL中消除重复列的有效技术,无论是简单地查找不重复的记录,还是实际删除重复行,都可以根据具体需求选择合适的方法。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/837555.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复