


MapReduce是一种编程模型,用于处理和生成大数据集,Terasort是一个基准测试程序,用于评估分布式存储系统的性能,它使用MapReduce框架来实现排序算法。
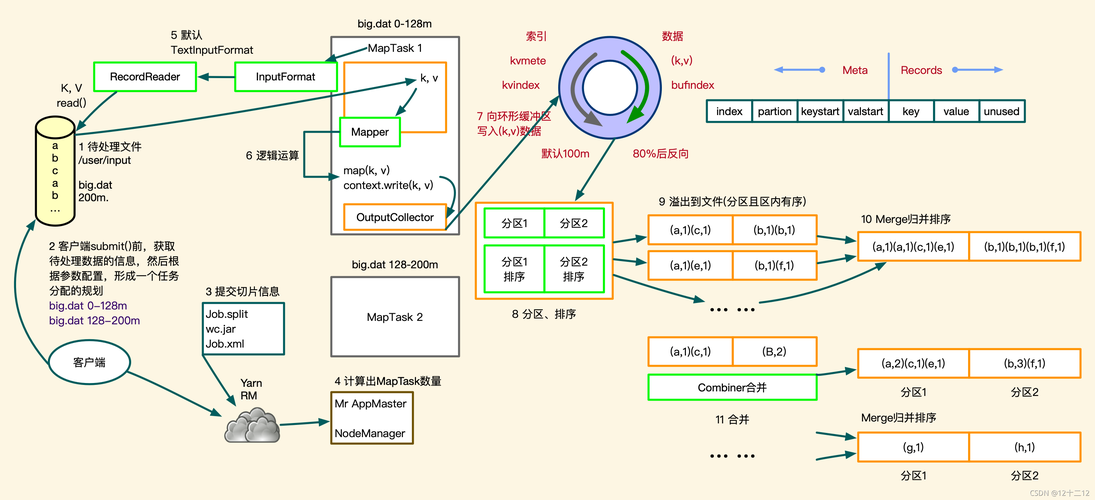

以下是Terasort MapReduce的详细步骤:
1、Mapper阶段:
输入:原始数据文件(通常是未排序的)
输出:键值对(keyvalue pairs),其中键是数据记录的一部分,值是整个数据记录
功能:将输入数据分割成多个键值对,每个键值对包含一个键和一个值,其中键是数据记录的一部分,值是整个数据记录。
2、Shuffle阶段:
输入:Mapper阶段的输出键值对
输出:按键分组的键值对列表
功能:将所有具有相同键的键值对组合在一起,形成一个新的键值对列表,其中键是唯一的,值是原始数据记录的列表。
3、Reducer阶段:
输入:Shuffle阶段的输出键值对列表
输出:排序后的数据记录
功能:对于每个键值对列表,按照键的顺序对值进行排序,并将排序后的值作为最终结果输出。
4、Combiner阶段(可选):
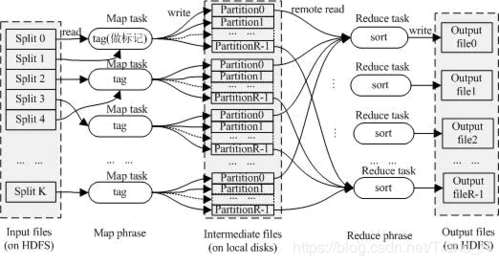
输入:Reducer阶段的中间输出
输出:局部排序后的数据记录
功能:在Reducer之前执行局部排序,以减少网络传输的数据量,Combiner可以在本地对每个键值对列表进行排序,然后将排序后的结果传递给Reducer。
5、Output阶段:
输入:Reducer阶段的输出
输出:最终排序后的数据记录
功能:将Reducer阶段的输出写入到最终的输出文件中。
以下是一个简化的伪代码示例,展示了Terasort MapReduce的基本结构:
Mapper函数
def mapper(input_data):
# 分割输入数据为键值对
key = extract_key(input_data)
value = input_data
return (key, value)
Reducer函数
def reducer(key, values):
# 对具有相同键的值进行排序
sorted_values = sort(values)
return sorted_values
MapReduce主函数
def mapreduce_terasort(input_files):
# 读取输入文件并映射数据
mapped_data = [mapper(file) for file in input_files]
# Shuffle阶段:按键分组键值对
shuffled_data = shuffle(mapped_data)
# Reduce阶段:对每个键值对列表进行排序
reduced_data = [reducer(key, values) for key, values in shuffled_data]
# 输出排序后的数据记录
output_sorted_data(reduced_data) 上述伪代码仅用于说明Terasort MapReduce的基本概念和流程,实际实现可能会涉及更复杂的细节和优化。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/836907.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复