


canal

1、背景
业务需求:阿里巴巴在杭州和美国的双机房部署,存在跨机房同步的业务需求。
发展历史:早期基于trigger获取增量变更,2010年后逐步尝试基于数据库日志解析。
2、支持版本
MySQL:支持mysql5.x版本的日志解析。
Oracle:支持部分版本的日志解析。
3、应用场景
数据库镜像:实时同步数据以构建数据库镜像。
多级索引:为卖家和买家各自分库索引提供支持。
canal工作原理
1、复制过程
记录变化:master将变化记录到二进制日志中。
拷贝事件:slave将binary log events拷贝到中继日志。
重做事件:slave重做事件,反映在自己的数据中。

2、配置canal
开启binlog功能:配置binlog模式为row。
配置管理用户:创建并授权canal用户。
3、部署步骤
下载解压:从github下载canal并解压。
修改配置:编辑instance.properties文件。
启动服务:运行startup.sh脚本,验证启动状态。
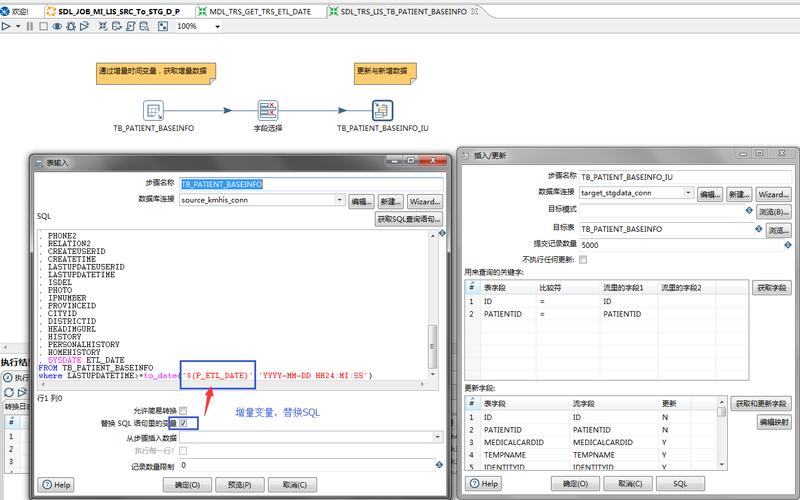
使用Binlog和Canal抽取数据
1、配置MySQL主节点
开启Binlog:修改my.cnf文件以开启Binlog。
设置格式:binlog_format必须设置为ROW。
2、启动Canal服务端
下载代码:从GitHub项目发布页下载Canal服务端代码。
配置文件:编辑conf/canal.properties和实例配置文件。
启动服务端:执行启动脚本,并在日志文件中查看输出。
3、编写Canal客户端
添加依赖:在项目中添加com.alibaba.otter:canal.client依赖项。
建立连接:构建CanalConnector实例并连接。
处理消息:轮询获取变更消息并处理。
ETL大数据集成工具比较
1、Sqoop
特点:支持全量和增量数据导入导出,适用于Hadoop与关系型数据库之间的数据传输。
适用场景:适用于大规模数据迁移和转换。
2、DataX
特点:阿里巴巴集团广泛使用的离线数据同步工具,支持多种异构数据源之间的数据同步。
适用场景:适用于异构数据库和文件系统之间的数据交换。
3、Kettle
特点:免费开源的ETL工具,提供图形化界面,易于配置和使用。
适用场景:适用于需要可视化设计和定时功能的数据抽取任务。
4、Canal
特点:基于数据库增量日志解析,提供增量数据实时订阅和消费。
适用场景:适用于需要实时数据同步的场景,如数据库镜像和实时备份。
5、StreamSets
特点:数据流任务的管理和监控,支持多种数据源和目标。
适用场景:适用于复杂的数据流处理和管道管理。
提供了一个全面的概览,包括canal和其他ETL工具的特点、工作原理和应用场景,以及如何配置和使用这些工具进行数据抽取和同步。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/836843.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复