


MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,全局排序是MapReduce的一个常见应用,它可以对大量数据进行排序,下面是一个使用MapReduce实现全局排序的详细步骤:
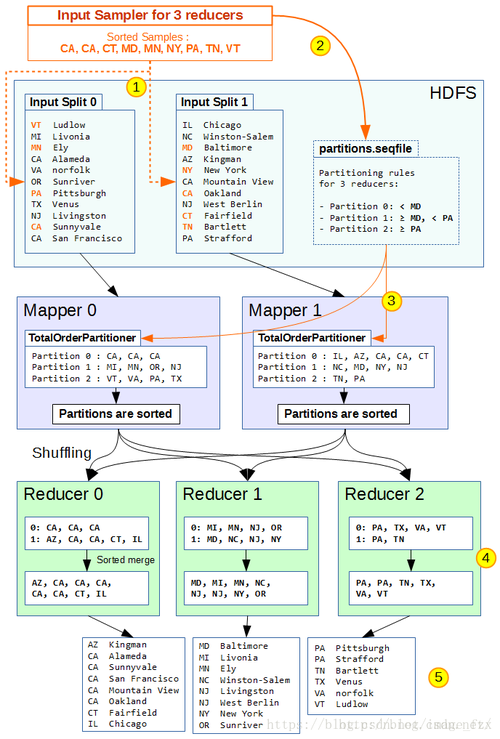

1. Map阶段
在Map阶段,我们将输入数据分割成多个键值对(keyvalue pairs),每个键值对表示一个元素及其对应的值,在这个例子中,我们假设输入数据已经按照键值对的形式给出。
def map(key, value):
# key: 输入数据的键
# value: 输入数据的值
# 输出格式为 (key, value)
yield key, value 2. Shuffle阶段
Shuffle阶段将Map阶段的输出按键值对的键进行排序和分组,这样,具有相同键的所有键值对都会被发送到同一个Reducer。
3. Reduce阶段
在Reduce阶段,我们对具有相同键的所有键值对进行处理,在这个例子中,我们将它们按照键的顺序进行排序。
def reduce(key, values):
# key: 相同的键
# values: 相同键对应的所有值的列表
# 输出格式为 (key, sorted_values)
sorted_values = sorted(values)
yield key, sorted_values 4. 全局排序

要实现全局排序,我们需要将所有Reducer的输出合并到一个文件中,并对这个文件进行排序,这可以通过以下步骤完成:
1、将所有Reducer的输出文件合并成一个大的中间文件。
2、对中间文件进行外部排序,得到最终的排序结果。
这个过程可以使用Hadoop或其他分布式计算框架来实现。
示例代码
以下是一个简单的Python代码示例,展示了如何使用MapReduce进行全局排序:
from mrjob.job import MRJob
from mrjob.step import MRStep
class GlobalSortJob(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper, reducer=self.reducer),
MRStep(reducer=self.final_reducer)
]
def mapper(self, _, line):
key, value = line.split()
yield int(key), int(value)
def reducer(self, key, values):
sorted_values = sorted(values)
yield key, sorted_values
def final_reducer(self, key, values):
for value in values:
yield key, value
if __name__ == '__main__':
GlobalSortJob.run() 这个示例代码使用了mrjob库来实现MapReduce作业,我们定义了一个名为GlobalSortJob的类,它继承自MRJob,我们定义了三个方法:mapper、reducer和final_reducer,分别对应于Map、Reduce和全局排序阶段,我们在steps方法中指定了这些阶段的执行顺序。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/836719.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复