


GROUP BY和HAVING子句结合使用。如果要查找具有重复来电号码的记录,可以编写以下查询语句:,,“sql,SELECT column_name, COUNT(*) as count,FROM table_name,GROUP BY column_name,HAVING count > 1;,“,,这将返回具有重复值的字段及其出现次数。在MySQL数据库管理中,查询和处理重复的记录是维护数据完整性与优化数据库性能的重要内容,本文将深入探讨如何有效识别并处理MySQL中的重复字段问题,特别是针对具有重复来电信息的数据库操作场景。

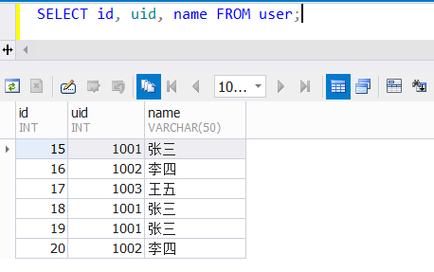
了解查询重复记录的基本方法,对于拥有id和name字段的表,如果需要找出name字段重复的所有数据,可以使用以下查询语句:
SELECT * FROMtable_nameAS a WHERE a.name IN (SELECT name FROMtable_nameGROUP BY name HAVING COUNT(*) > 1);
此查询首先通过子查询选取name字段, 并通过GROUP BY语句结合HAVING COUNT(*) > 1条件筛选出出现次数大于1的记录,即重复的name值,主查询则返回这些重复name字段对应的所有记录。
进一步地,如果想要获取所有数据的分组情况以及重复数据的具体重复次数,可以使用如下查询:
SELECT COUNT(name) AS '重复次数', name FROMtable_name GROUP BY name HAVING COUNT(name) > 1; 此语句不仅会显示哪些name字段重复,还会展示每个重复字段的具体重复次数,有助于进一步分析处理重复数据。
在特定场景下,如查找单个字段(例如account)中的重复数据,可以采用类似的查询策略,这涉及到使用COUNT函数和GROUP BY子句来识别数量大于1的记录,从而确定重复项。
理解了基本查询方法后,考虑如何在具有多个可能重复字段的情况下进行查询,在一个包含first_name、last_name和email字段的contacts表中,可能会遇到姓名和电子邮件地址都有重复的情况,在这种情况下,可以按照以下方式进行查询:
SELECT first_name, last_name, email, COUNT(*) as DuplicateCount
FROMcontacts
GROUP BY first_name, last_name, email
HAVING COUNT(*) > 1; 此查询将展示姓、名和电子邮件地址都相同的记录,并通过DuplicateCount列示每个重复组的数量。
在处理重复记录时,一个常见的需求是删除或更新这些重复项,可能需要保留每组重复记录中的一条,并删除其余的,这通常涉及更复杂的SQL操作,比如使用窗口函数或临时表来标记并操作重复项。
在处理MySQL中的重复字段时,关键在于使用GROUP BY和HAVING子句来识别重复项,并通过适当的查询和操作来管理这些数据,理解这些技术的应用不仅可以帮助消除不必要的数据冗余,还能提升数据库的整体性能和准确性。
FAQs
Q1: 如何处理名称字段中的大小写导致的重复?
A1: 名称字段中的大小写可能会导致看似重复但实际上是不同的记录,处理这种情况的一种方法是在查询时使用LOWER()或UPPER()函数,将字段转换为统一的大小写格式,从而避免因大小写不同造成的重复。
Q2: 是否可以使用程序自动处理所有类型的重复数据?
A2: 虽然可以使用程序自动处理许多类型的重复数据,但在某些情况下仍需要人工判断,两条记录可能在非关键字段上有所不同,却共享一个关键的重复字段,自动处理可能会错误地删除或修改信息,设计自动化脚本时,应确保充分理解数据结构,并在全面测试后应用于生产环境。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/836324.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复