


在MapReduce框架中,Combiner是一个重要的优化组件,它的主要作用是在Map阶段输出键值对后,对数据进行局部汇总,从而减少数据传输量和提高整体作业性能,下面将深入探讨如何有效地应用开发MapReduce的Combiner功能:
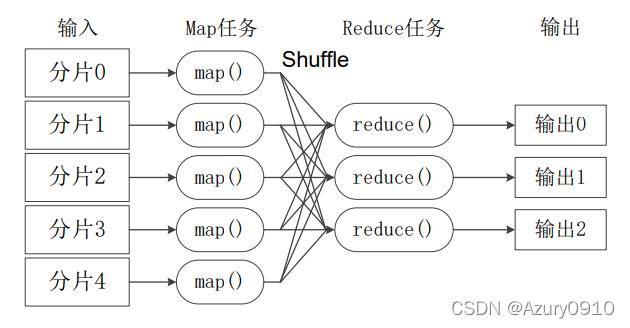

1、Combiner的基本作用
减少数据传输量:Combiner通过在Map阶段输出后进行局部汇总,减少了数据在网络中的传输量,这对于大数据处理尤为重要,可以显著提高网络IO性能。
提高数据处理效率:由于Reducer需要处理的数据量减少,Combiner间接减少了Reduce阶段的负担,从而提高了整个MapReduce作业的性能。
2、Combiner的适用场景
大数据量处理:在处理大量数据时,Combiner能够有效减少数据传输的开销,尤其是在数据传输成本较高的分布式环境中。
局部聚合有意义:Combiner适合在数据局部聚合有意义的场景使用,例如计数、求和等操作,这些操作在Mapper端就能够部分完成,减轻Reducer的工作负载。
3、Combiner的实现原理
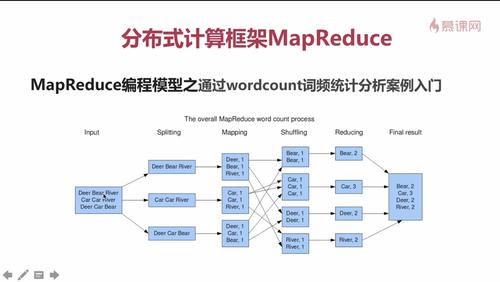
继承Reducer类:Combiner组件的父类就是Reducer,它的实现逻辑与Reducer类似,不同之处在于运行的位置和处理的数据范围。
局部数据汇总:Combiner只在每个Map任务的输出上进行操作,即对每个Mapper的输出结果进行局部汇总,不影响全局数据的处理结果。
4、Combiner的优缺点
优点:包括减少数据传输量、减轻网络负担、提高MapReduce作业的整体效率等。
缺点:对于一些特殊应用场景,错误使用Combiner可能会得到错误的结果,因为Combiner改变了数据流向和处理逻辑。
5、如何选择合适的Combiner
数据局部特性分析:分析数据处理的特点,确定哪些操作适合在Map端进行局部汇总。
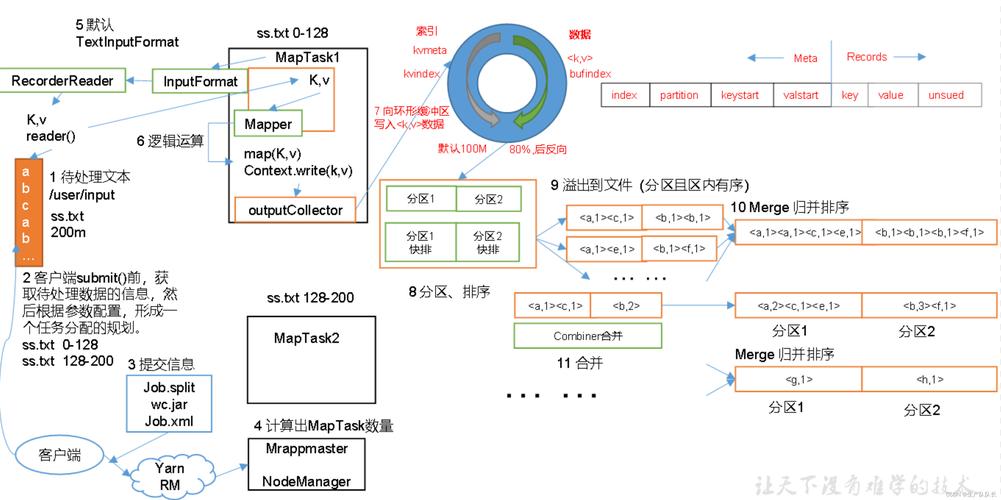
性能考量:评估使用Combiner后的性能提升,与不使用Combiner的情况作比较,确保性能优化效果。
6、编程实践建议
配置合理:在MapReduce作业配置中,合理设置Combiner,根据数据特点和资源情况调整。
测试充分:在投入生产环境前,应充分测试Combiner的功能和性能,确保其符合预期效果。
7、注意事项和限制
避免全局操作:不要在Combiner中执行需要全局数据的操作,这可能会导致结果的错误。
数据类型考虑:在选择使用Combiner时,要考虑数据的类型和结构,确保Combiner能够正确处理。
8、工具和平台支持
Hadoop平台:Apache Hadoop原生支持Combiner的设置和使用,用户可以通过配置文件轻松启用Combiner。
云服务平台:例如阿里云的EMapReduce(EMR)等云服务提供了易于使用的界面和API接口,方便用户快速实现和管理大数据处理作业,包括使用Combiner进行优化。
以下是关于MapReduce Combiner的应用开发建议,通过单元表格的形式整理出关键信息:
| 开发建议 | 描述 | 示例或注意事项 |
| 数据局部聚合 | 选择适合局部汇总的操作,如计数、求和等 | 避免全局操作导致结果错误 |
| 性能评估 | 对比使用与不使用Combiner的性能差异 | 确保性能优化效果 |
| 合理配置 | 根据实际数据量和处理需求设置Combiner | 在Hadoop配置文件中设置 |
| 充分测试 | 在生产环境部署前,进行充分的功能和性能测试 | 测试Combiner的正确性和性能影响 |
| 注意数据类型 | 考虑数据类型和结构,确保Combiner能正确处理 | 避免因数据类型不匹配导致处理异常 |
| 使用云服务 | 利用云服务平台简化大数据处理作业的配置和管理 | 如阿里云EMR提供的界面和API接口 |
可以看到合理应用MapReduce的Combiner不仅能有效减少网络数据传输量,还能显著提高数据处理的效率,在开发过程中,应注意选择合适的场景和操作,进行充分的测试,并利用成熟的大数据处理平台进行优化配置,通过上述建议,用户可以最大化MapReduce作业的性能,同时保证数据处理的准确性和稳定性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/835720.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复