

在当今数据驱动的世界中,机器学习模型的训练越来越依赖于大量多样化的数据,由于数据分布在不同的组织和设备中,加之隐私保护的要求,使得这些数据的集中处理变得极具挑战,MapReduce作为一种编程模型,能够有效支持大规模数据集的分布式计算,而迁移学习则能够在源任务上学到的知识迁移到目标任务中,以解决目标任务数据量不足的问题。
MapReduce与迁移学习的结合使用,为处理大规模、分布式数据集提供了新的可能,在这种结合下,MapReduce负责数据的并行处理,而迁移学习则利用来自其他领域或任务的知识,提高新任务的学习效率和性能,这种跨领域的知识迁移特别适用于那些数据稀缺的场景,如医疗诊断或个性化推荐系统等。
MapReduce的核心机制是将问题分解为两部分:Map阶段和Reduce阶段,Map阶段负责将数据分成小块并独立处理每一块,而Reduce阶段则是聚合Map阶段的结果,输出最终结果,这种模型非常适合于大数据环境下的并行处理需求,可以显著提高数据处理的速度和效率。
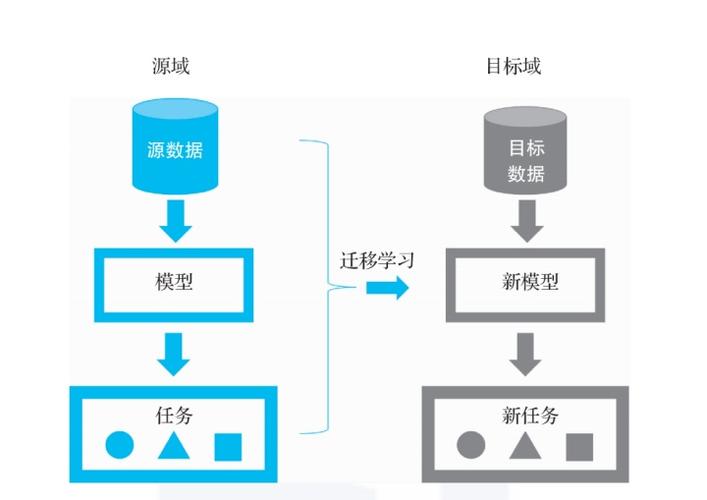
迁移学习是一种利用已有知识解决新问题的技术,它通过将一个领域(源领域)中学到的知识应用到另一个相关但不同的领域(目标领域),来减少大量的标注工作和训练时间,迁移学习尤其适合于那些难以获取大量标注数据的应用场景,如专业领域的图像识别或小众语言的文本处理。
在实际应用中,MapReduce与迁移学习的结合通常涉及到跨域的数据共享和模型训练,在联邦学习的场景下,多个参与者各自保有本地数据,共同训练一个全局模型,MapReduce框架可以在此过程中用于并行处理各参与者的本地数据,而迁移学习技术则帮助参与者利用其他参与者的知识,改善本地模型的性能。
考虑到数据安全和隐私保护的重要性,联邦转移学习(FTL)提出了一种解决方案,该方案在隐私保护的环境下,利用迁移学习为联邦学习中样本和特征空间提供辅助,这种方法不仅提高了模型的性能,而且保护了数据的安全和用户的隐私。
MapReduce和迁移学习的结合是处理分布式数据和提升机器学习模型性能的有效手段,通过MapReduce进行高效的数据并行处理,再结合迁移学习在不同任务之间迁移知识,可以在保证数据隐私的前提下,提高模型在新领域的适用性和精确性,这种技术融合的策略,为未来机器学习的应用开辟了新的可能性和方向。
FAQs
什么是MapReduce?
MapReduce是一种编程模型,用于大规模数据集的并行运算,它将任务分为两个基本的阶段:Map阶段和Reduce阶段,Map阶段对数据进行分割并处理,Reduce阶段则对处理后的结果进行汇总,这种模型特别适合于大数据分析,能够有效地提高处理速度和效率。
迁移学习有哪些应用场景?
迁移学习的应用场景广泛,特别是在数据量有限的情况下表现出色,常见的应用场景包括小样本学习、领域适应、多任务学习和跨领域推荐系统等,在医疗领域,迁移学习可以从公开的医学图像数据集中学习知识,帮助改善特定疾病的图像识别模型。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/835277.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复