


MapReduce如何工作
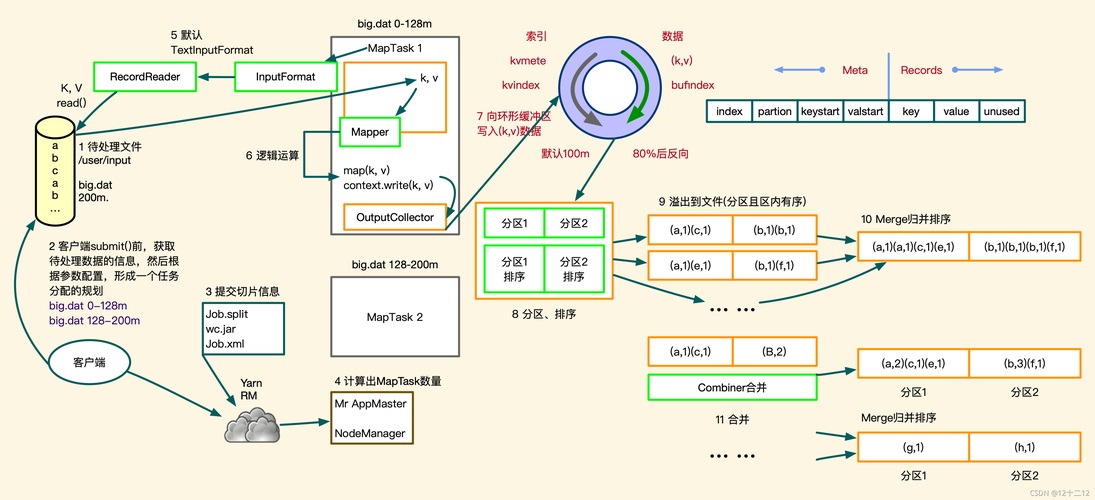

MapReduce 是一种编程模型,用于大规模数据集(大于1TB)的并行运算,其基本思想是将问题分而治之,将大问题分解成小问题,然后分别求解,最后再合并结果,MapReduce的工作过程可以分为以下几个步骤:
1、数据输入
数据读取:从HDFS中读取文件,数据读取组件是TextInputFormat和LineRecordReader。
数据分片:调用Job.steInputFormaiClass,将输入文件划分为大小相等的小数据块。
2、Map阶段
格式化数据源:输入Map阶段的数据源,必须经过分片和格式化操作。
执行Mapper函数:对每个小数据块执行Mapper函数,生成一系列键值对。
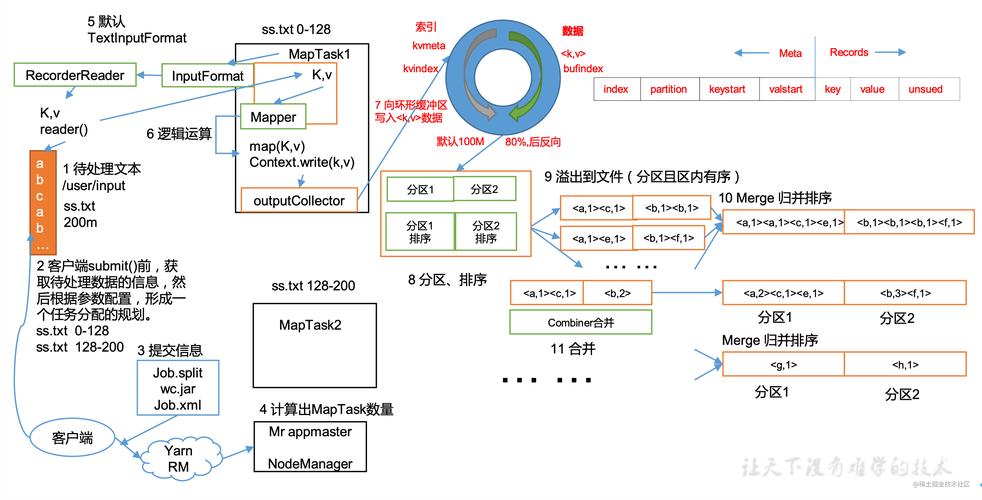
3、Shuffle阶段
排序:对Mapper输出的键值对进行排序。
分组:将具有相同键的值放在一起,为Reduce阶段做准备。
4、Reduce阶段
执行Reducer函数:对每个键,执行Reducer函数,合并键相同的值,生成另外一系列键值对。
输出结果:将Reducer的输出写入HDFS。
如何使用MapReduce命令

使用MapReduce命令主要包括以下步骤:
1、准备环境
安装Hadoop:首先需要在计算机上安装Hadoop环境。
配置环境变量:配置HADOOP_HOME和PATH环境变量,确保可以在命令行中运行Hadoop命令。
2、编写MapReduce程序
编写Mapper类:定义一个继承自Mapper的类,重写map方法,实现映射逻辑。
编写Reducer类:定义一个继承自Reducer的类,重写reduce方法,实现归约逻辑。
3、编译打包
编译Java程序:使用Java编译器编译编写的MapReduce程序。
打包成JAR文件:使用jar命令将编译后的class文件打包成一个JAR文件。
4、运行MapReduce作业
上传JAR文件到HDFS:使用hadoop fs put命令将JAR文件上传到HDFS。
运行MapReduce作业:使用hadoop jar命令运行MapReduce作业,指定主类、JAR文件和输入输出路径。
MapReduce是一种强大的分布式计算模型,通过将大问题分解成小问题,分别求解后再合并结果,可以处理大规模数据集,使用MapReduce命令需要编写MapReduce程序,编译打包后上传到HDFS,然后使用hadoop jar命令运行,通过学习和实践,可以更好地理解和掌握MapReduce的使用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/835204.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复