

在MySQL数据库中应用随机森林回归算法涉及到多个关键步骤,包括数据处理、模型训练、参数调优等,下面将详细介绍这一流程:
1、数据准备与预处理
理解数据结构:要清楚MySQL数据库中的数据结构,了解各表之间的关系以及字段的含义,这是建模的基础。
数据抽取:根据需求从数据库中抽取相关数据,这可能涉及SQL查询、数据清洗及转换等操作。
特征工程:选取或构造对预测任务有帮助的特征,可能需要进行特征选择或特征转换以更好地适应模型。
2、随机森林回归模型理解
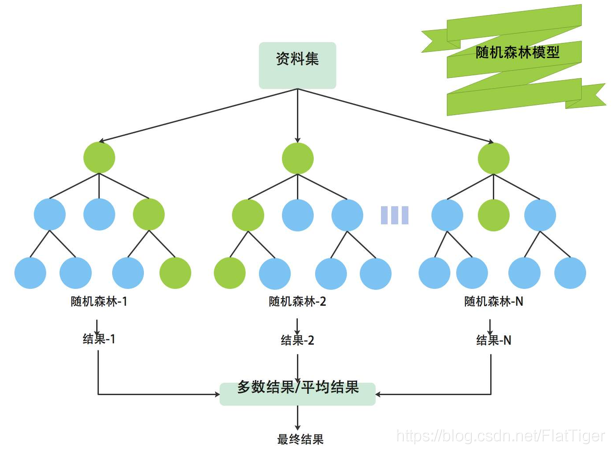
模型概念:随机森林回归是通过构建多棵决策树,并取其平均值来提高预测精度的一种算法。
模型优势:该模型在处理大数据集时具有较好的鲁棒性,并且对数据维度的要求相对较低。
适用范围:适用于需要处理中等维度数据且对预测准确性有较高要求的场景。
3、模型训练与验证
训练集测试集划分:从准备好的数据集中划分出训练集和测试集,用于模型的训练和验证。
超参数选择:合理选择树的数量、树的深度、特征子集的大小等超参数对模型性能至关重要。
交叉验证:使用交叉验证等方法评估模型的泛化能力,避免过拟合现象。
4、特征和样本的随机抽取
样本随机抽取:从原始数据集中随机抽取样本进行模型训练,抽样时可以允许样本重复。
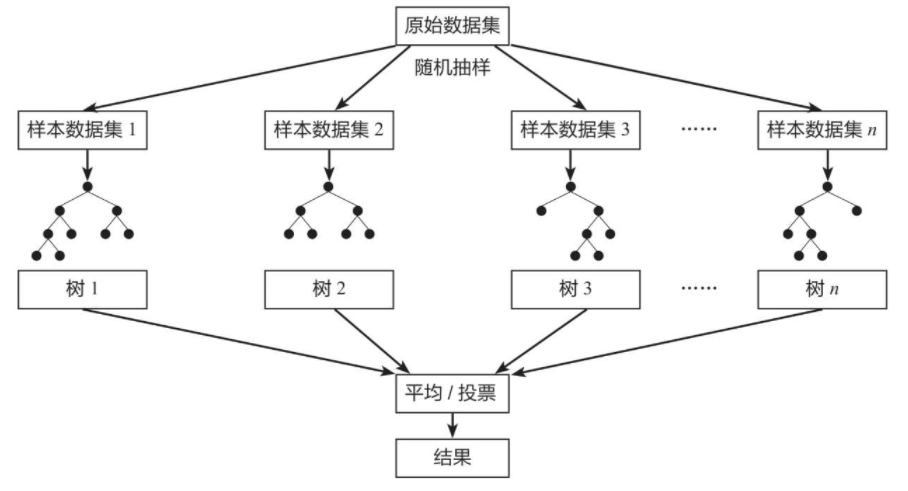
特征随机选择:在构建每棵树时,从所有特征中随机选取一个子集,增加模型的多样性。
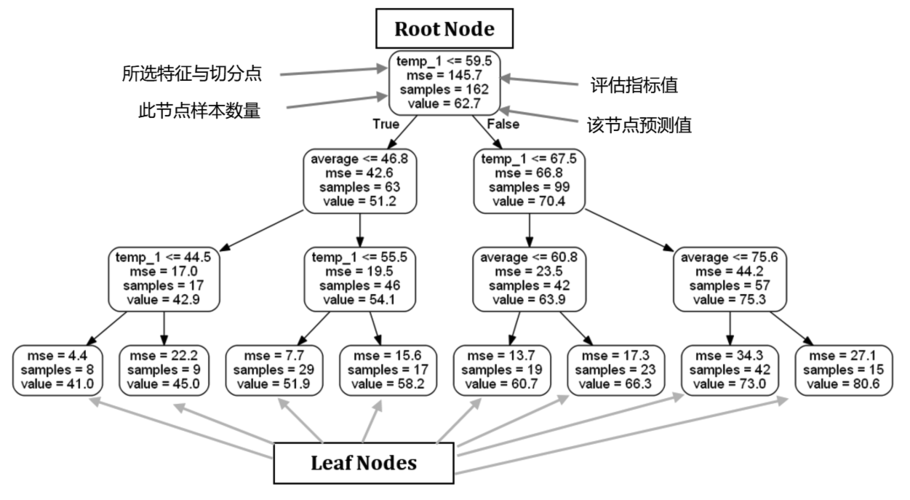
5、决策树构建与集成
构建决策树:基于抽取的样本集和特征集,分别训练出多棵决策树。
树的组合:将所有决策树的预测结果进行汇总,一般采用平均的方式得到最终的回归预测结果。
6、模型评估与调优
性能指标选择:根据回归任务的特点,选择合适的性能指标,如MSE(均方误差)或MAE(平均绝对误差)。
模型调优:根据模型评估结果调整模型参数,如增加树的数量,调优特征选择策略等,以提高模型性能。
在了解上述内容后,还可以关注以下几个方面:
数据质量对模型的影响巨大,因此在数据预处理阶段需要特别注意数据清洗和异常值处理。
对于大型数据集,可以考虑使用数据采样技术来减少训练时间,同时保证模型的效果。
在随机森林回归模型训练过程中,应注意避免因单个决策树的过度复杂而导致的过拟合问题。
应定期重新训练模型并更新特征集,以适应可能的数据趋势变化和新的业务需求。
随机森林回归算法在MySQL数据库上的应用是一个系统的过程,涉及从数据预处理到模型训练、评估和调优的多个环节,通过精心的数据准备和恰当的模型参数设置,可以充分利用随机森林回归模型的优势,实现较为准确的预测,在实际操作中,需要注意数据的实时性和准确性,并适时地更新模型以应对业务的变化。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/834235.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。