


在当今大数据时代,支持向量机(SVM)作为一种有效的分类器,广泛应用于数据分析和机器学习领域,随着数据量的剧增,传统的SVM算法在处理大规模数据集时面临计算量大、训练时间长的挑战,MapReduce编程模型的出现,为解决这一问题提供了新的思路,本文旨在深入探讨如何通过MapReduce技术优化SVM算法,以适应大规模数据处理的需求。

了解SVM算法的基本原理至关重要,SVM是一种监督学习算法,通过在多维空间中寻找最优的超平面来区分不同的类别,在处理大规模数据集时,SVM需要大量的计算资源进行核函数的计算和参数的优化,这常常导致训练过程缓慢且效率低下。
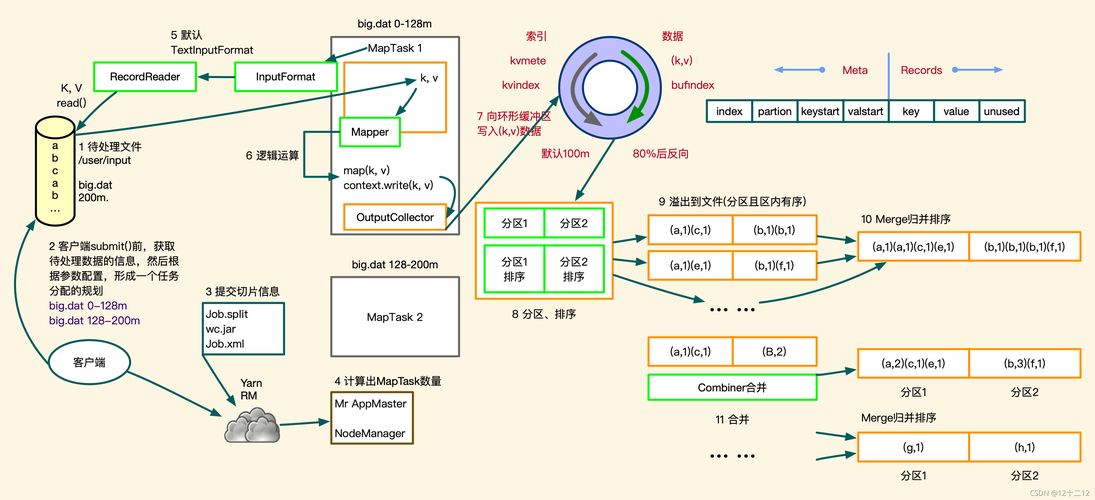
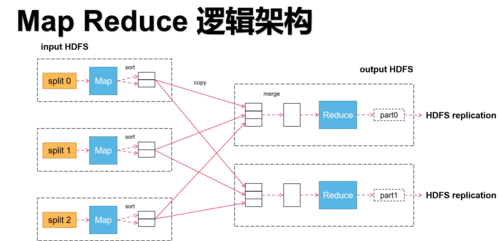
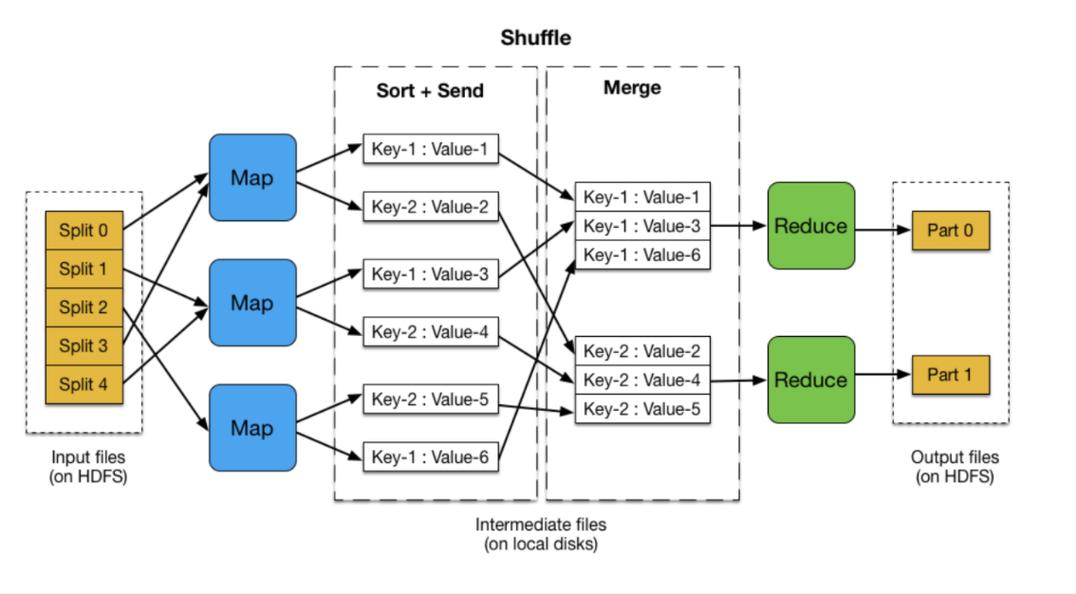
MapReduce编程模型由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分成多个小片段,每个片段由一个节点独立处理;而在Reduce阶段,各个节点的处理结果将被整合得到最终结果,这种模型非常适合于并行处理大量数据,将SVM算法与MapReduce结合使用,有望显著提升其在大规模数据集上的训练速度和效率。
针对SVM在大规模数据集上的应用,研究者们提出了多种基于MapReduce的并行策略,MRIISVM算法就是基于MapReduce编程模型的一种实现,在这种算法中,Map节点之间独立运行,无需像传统基于MPI编程那样进行频繁的通信,大大减少了通信开销并提高了计算效率,这种并行策略充分利用了MapReduce模型的优势,使得SVM的训练过程更加高效。
进一步地,对于MapReduce SVM的具体实现,可以将其分为三个主要步骤:数据预处理、Map阶段和Reduce阶段,在数据预处理阶段,大规模数据集首先被划分为多个子集,并分配给不同的计算节点,接着在Map阶段,每个节点对其分得的数据子集执行SVM训练,计算出局部的支持向量,在Reduce阶段,所有节点的局部支持向量被汇总,形成全局的支持向量,并用于构建最终的分类模型。
为了确保MapReduce SVM算法的有效性和可行性,需要考虑几个关键因素,首先是数据的划分策略,合理划分数据可以保证各个节点负载均衡,避免个别节点成为性能瓶颈,其次是容错性设计,由于大规模集群中节点故障是常态,算法应能自动应对节点失效,保证计算任务的顺利完成。
在实施过程中,还需要注意优化算法参数和内核函数的选择,不同类型和规模的数据可能需要不同的SVM参数和内核函数以达到最佳训练效果,进行参数调优和选择合适的内核函数对于提升算法性能至关重要。
将SVM算法与MapReduce技术相结合,在理论上和实践中都被证明是一种有效解决大规模数据处理问题的方法,通过并行化处理,可以显著提高SVM的训练速度和处理能力,使其更好地适应大数据环境的需求。
FAQs
Q1: MapReduce SVM算法的主要优点是什么?
A1: MapReduce SVM算法的主要优点是能够显著提高SVM在大规模数据集上的训练速度和效率,通过并行处理技术,该算法降低了单节点的计算负担,减少了通信开销,从而加快了数据处理速度,使其更适合于处理海量数据。
Q2: 实施MapReduce SVM算法需要注意哪些问题?
A2: 实施MapReduce SVM算法时,需要注意数据划分策略以确保各节点负载均衡,进行容错性设计以应对节点故障,以及优化算法参数和内核函数选择以提高算法性能,合理的系统配置和高效的资源管理也是确保算法顺利执行的重要因素。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/832640.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复