


MapReduce全排序
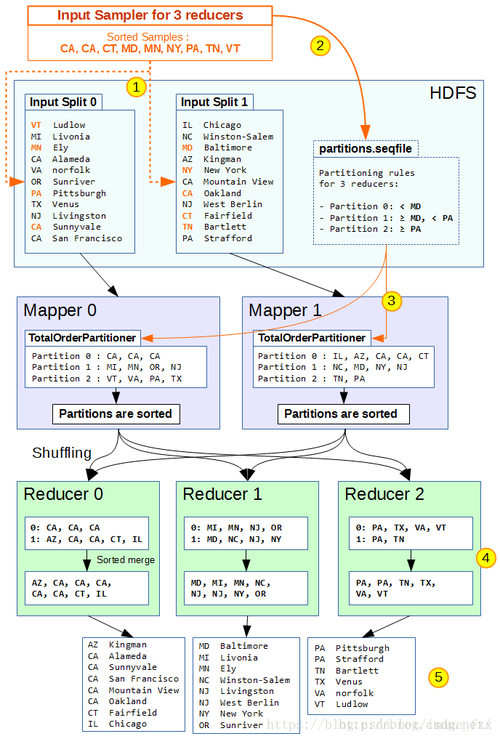

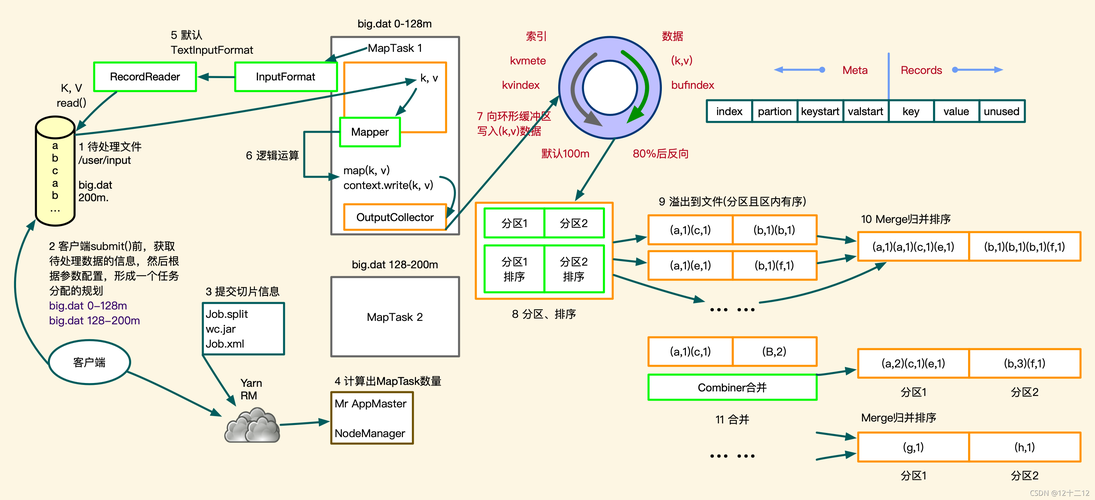
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由Google公司提出,并广泛应用于分布式计算环境中,在MapReduce中,数据被分成多个独立的块,每个块在不同的节点上进行处理,这种模型非常适合进行大规模数据处理任务,如全排序。
1. Map阶段
Map阶段的任务是将输入数据转换为一组键值对(keyvalue pairs),在这个例子中,我们将输入数据视为一组整数,并将每个整数映射到一个键值对,其中键是整数本身,值是一个空字符串,这样,我们可以将所有相同的整数聚集在一起,以便后续的Reduce阶段可以对其进行排序。
def map_function(data):
for number in data:
yield (number, "") 2. Shuffle阶段
Shuffle阶段的任务是将Map阶段的输出按照键进行排序和分组,由于我们的键就是整数本身,所以它们会自动按照数字大小进行排序,这个阶段会将具有相同键的所有键值对发送到同一个Reducer。
3. Reduce阶段
Reduce阶段的任务是对每个键值对组进行处理,以产生最终的结果,在这个例子中,我们不需要对键值对做任何处理,因为我们只需要按照键的顺序输出它们即可,Reduce函数只需简单地遍历每个键值对组,并输出键。
def reduce_function(key, values):
for value in values:
yield key 4. 运行MapReduce作业
要运行这个MapReduce作业,我们需要一个MapReduce框架,如Hadoop或Apache Spark,这些框架提供了执行MapReduce作业所需的基础设施和调度器,以下是使用伪代码描述的大致步骤:
1、初始化MapReduce作业配置。 2、设置输入数据的路径。 3、指定map函数和reduce函数。 4、提交作业到集群。 5、等待作业完成。 6、获取排序结果。
FAQs
Q1: MapReduce全排序的时间复杂度是多少?
A1: MapReduce全排序的时间复杂度取决于具体的实现和使用的排序算法,MapReduce中的排序操作的时间复杂度为O(n log n),其中n是输入数据的数量,这是因为MapReduce框架通常会使用某种形式的归并排序或外部排序算法来处理排序任务。
Q2: MapReduce全排序是否适用于非数值类型的数据?
A2: MapReduce全排序主要适用于可以比较的数据类型,例如整数、浮点数或字符串,对于非数值类型的数据,需要定义适当的比较函数来确定排序顺序,如果数据类型无法直接比较,可能需要额外的预处理步骤来转换数据类型或提取可比较的特征。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/832516.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复