

MapReduce 是一个用于大规模数据处理的编程模型,它的核心思想是将大任务分解为多个小任务,然后并行处理这些小任务,最后将结果合并,在这个过程中,文件名的指定和迁移是一个重要的环节,下面将详细介绍如何在 MapReduce 中进行文件名的指定和迁移。
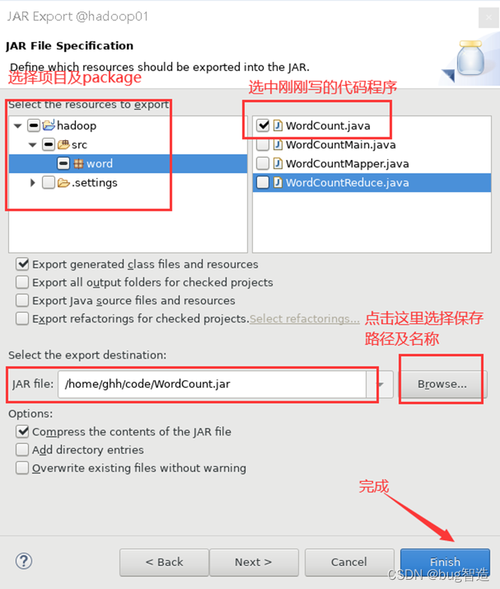

1. 文件名的指定
在 MapReduce 中,我们需要指定输入文件和输出文件的名称,这可以通过以下方式实现:
输入文件名:在 MapReduce 作业的配置中,我们需要设置输入路径,即输入文件所在的 HDFS 路径。
FileInputFormat.setInputPaths(conf, new Path(inputPath));
输出文件名:在 MapReduce 作业的配置中,我们需要设置输出路径,即输出文件将被写入的 HDFS 路径。
FileOutputFormat.setOutputPath(conf, new Path(outputPath));
2. 文件名的迁移
在 MapReduce 中,文件名的迁移通常是指将处理后的数据写入到新的文件中,以便于后续的处理和分析,这可以通过以下方式实现:
在 MapReduce 作业的配置中,设置输出路径,即输出文件将被写入的 HDFS 路径。
FileOutputFormat.setOutputPath(conf, new Path(outputPath));
在 MapReduce 作业的 reduce 阶段,将处理后的数据写入到指定的输出文件中。
context.write(key, value);
这样,处理后的数据就会被写入到指定的输出文件中,实现了文件名的迁移。
3. 注意事项
输入文件和输出文件的路径必须是 HDFS 路径,不能是本地文件系统路径。
输出文件如果已经存在,将会被覆盖,如果需要保留原文件,请先进行备份。
MapReduce 作业运行完成后,可以通过 Hadoop 命令行工具查看和下载输出文件。
通过以上步骤,我们可以在 MapReduce 中实现文件名的指定和迁移。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/832496.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复