


在操作MySQL数据库时,处理重复数据是一项重要的任务,本文将详细介绍如何在MySQL中防止数据重复、查询不重复的数据以及管理这些重复数据的有效方法,具体分析如下:

1、设置唯一性约束
定义主键 (PRIMARY KEY):在MySQL中,可以通过定义PRIMARY KEY来防止数据表中出现重复的记录,主键是唯一识别数据库表中每一条记录的字段或字段组合,确保了表中每条数据的唯一性,如果有一个用户表,可以使用用户ID作为主键,保证每个用户都有唯一的标识。
使用唯一索引 (UNIQUE):除了主键之外,MySQL还提供了UNIQUE索引的方式来保证数据的唯一性,UNIQUE索引允许你在不是主键的列上强制数据的唯一性,这意味着,即使你不使用某个字段作为主键,也能确保该字段中的值是唯一的。
2、查询不重复的数据
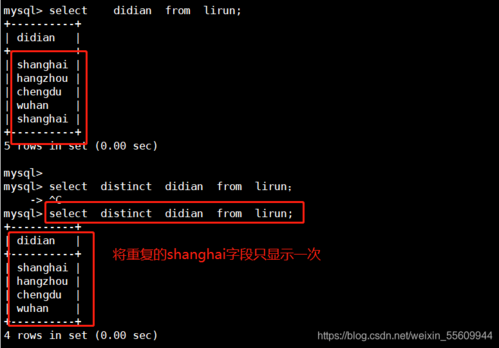
使用DISTINCT关键字:在查询数据时,如果你需要去除结果集中的重复行,可以使用DISTINCT关键字,这个关键字能够帮助你获取到无重复的数据集合,选择不重复的用户名,你可以这样写:SELECT DISTINCT username FROM users;。
利用GROUP BY子句:另一种去重的方式是通过GROUP BY子句,当你根据某个字段对数据进行分组时,GROUP BY会将具有相同值的记录聚合在一起,从而避免重复,虽然它主要用于聚合计算,但也能有效减少查询结果中的重复。
3、处理现有的重复数据
检测并统计重复:为了处理已存在的重复数据,首先需要进行检测和统计,可以通过编写特定的SQL查询,结合GROUP BY和HAVING子句来找出哪些数据存在重复,并统计其出现的次数,如果你想找出重复的邮箱地址,可以使用如下查询:SELECT email, COUNT(*) as count FROM users GROUP BY email HAVING count > 1;
删除或合并重复数据:在确认了哪些数据是重复之后,你可以选择删除这些重复的数据或者将它们合并成一条记录,这需要根据业务需求来决定,合并数据可能涉及到数据的平均、求和等操作,而直接删除则可能需要更加小心,以防误删重要信息。
在实际操作中,还应注意以下几点以确保数据的准确性和完整性:
谨慎操作主键和唯一索引:定义主键和唯一索引时需确保字段的值不会为NULL,因为NULL值也被视为唯一,这可能会影响数据的插入和更新。
考虑性能影响:频繁地使用DISTINCT或GROUP BY可能会对数据库性能产生影响,尤其是在处理大量数据时,设计查询时应考虑到效率问题。
备份重要数据:在进行数据去重操作前,建议先备份相关数据,以防操作失误导致不可逆的数据丢失。
可以有效地处理MySQL中的重复数据问题,确保数据库的准确性和高效运行,将通过相关问答FAQs进一步解答一些具体疑问。
相关问答FAQs
Q1: 如何确定是否需要在表中设置主键还是唯一索引?
A1: 主键用于唯一标识表中的每一条记录,适用于那些自然唯一的字段,如用户ID,而唯一索引适用于需要在非主键字段上强制唯一性的情况,如邮箱地址、身份证号等,选择哪种方式取决于你的数据结构和业务需求。
Q2: 如果表中已经存在重复数据,如何使用SQL语句找到并删除这些重复项?
A2: 可以先通过GROUP BY和HAVING子句找到重复数据,然后根据情况决定是直接删除还是进行合并处理,删除用户表中重复的邮箱地址,可以先执行查询找出这些邮箱,然后根据实际业务逻辑决定如何处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/832421.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复