


MapReduce模型是大数据处理领域的一种核心编程模型,广泛用于分布式计算,下面将详细探讨MapReduce的开发商、模型原理、核心功能以及编程实现等方面,以深入理解这一开创性的技术:


MapReduce的起源与发展
1、起源与普及
初创理念:MapReduce最初由Google提出,旨在简化大规模数据集处理。
开源发展:随后由Apache Hadoop项目继承并发展,成为大数据处理的标准框架之一。
2、影响与评价
改变计算模式:MapReduce改变了我们组织和执行大规模计算的方式,使得分布式计算更加高效与可靠。
广泛应用:其思想被广泛应用于各种数据处理场景,如日志分析、数据挖掘等。
3、未来趋势
持续优化:随着计算需求的增加,MapReduce模型也在不断优化升级,以适应更大规模的数据处理需求。
技术创新:新的计算模型如Apache Spark等也逐渐兴起,但MapReduce依旧是很多企业的首选。
MapReduce的工作原理
1、Map阶段
任务分配:输入数据被分成小块,每块分别由不同的Map任务处理。
数据处理:每个Map任务生成键值对作为输出,供下一阶段使用。
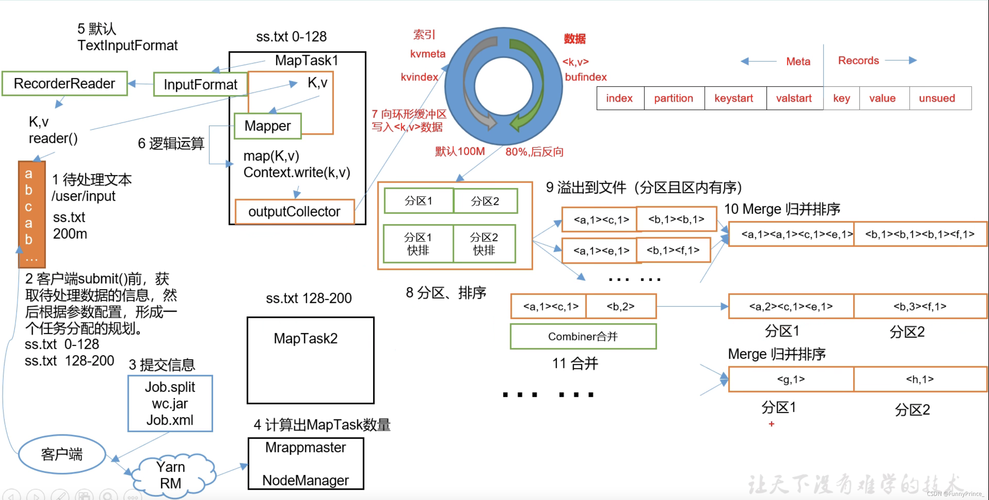
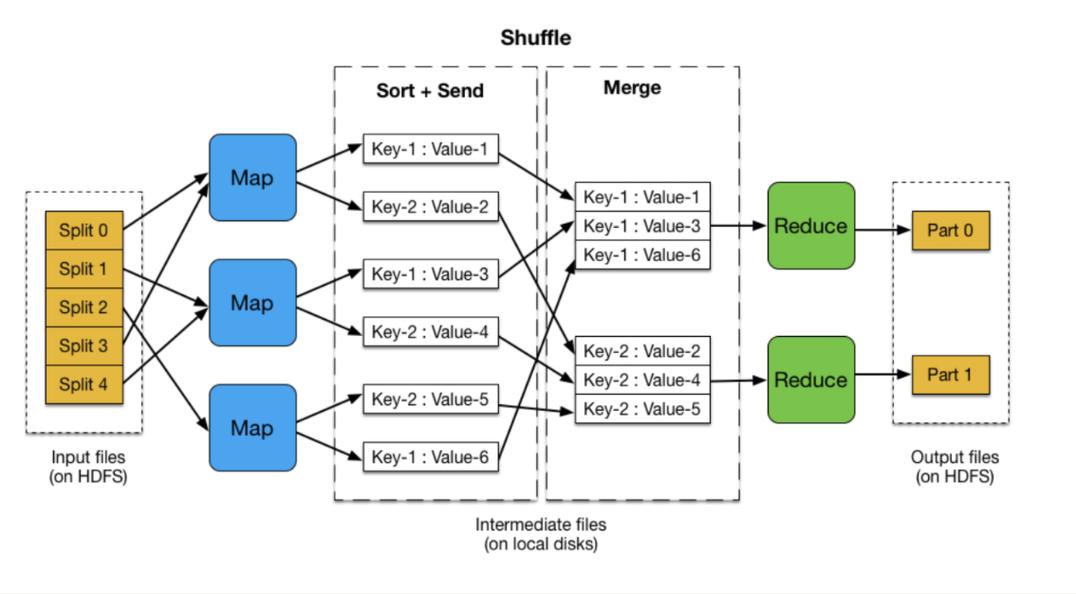
2、Shuffle阶段
数据排序:将Map阶段的输出根据键值进行排序和分区。
数据传输:将排序后的数据发送给对应的Reduce任务。
3、Reduce阶段
数据汇总:对从Shuffle阶段接收到的数据进行汇总或加工处理。
结果输出:最终生成的结果数据可以用于进一步的处理或存储。
MapReduce的核心功能
1、扩展性与可靠性
高扩展性:通过添加更多节点轻松扩展计算能力。
容错机制:自动重新执行失败的任务,保证数据处理的稳定性。
2、资源管理与调度
优化资源使用:合理分配计算资源,提高集群利用率。
任务调度:动态调整任务执行策略,确保作业平稳运行。
3、数据处理能力
支持多种数据格式:能够处理不同格式的大规模数据集。
高性能计算:通过并行处理加快数据处理速度,提升效率。
4、易用性与灵活性
简单的编程模型:用户只需实现Map和Reduce函数即可。
广泛的适应性:适用于各种需要大规模数据处理的场景。
编程实现与接口
1、编程接口
API设计:提供简洁的编程接口,便于开发者快速上手实现自定义的业务逻辑。
代码实现:用户需编写Map和Reduce函数,定义数据处理的逻辑。
2、设计模式与最佳实践
设计模式应用:鼓励使用已知的设计模式来优化MapReduce作业。
最佳实践分享:社区中分享的经验帮助避免常见错误,提高开发效率。
MapReduce不仅是一种创新的编程模型,也是处理海量数据的强大工具,其简洁高效的设计理念使其在大数据领域得到了广泛应用,而持续的技术革新保证了其在未来的数据处理领域仍将保持重要地位。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/831884.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复