


MapReduce流程顺序和Join顺序的Hint是关键优化技术,用于指导数据处理框架如何高效地执行作业。通过合理设置这些Hint,可以显著提高大数据处理的性能和效率。
MapReduce的流程顺序和Join顺序的Hint

(图片来源网络,侵删)
深入了解MapReduce框架及优化Join操作策略
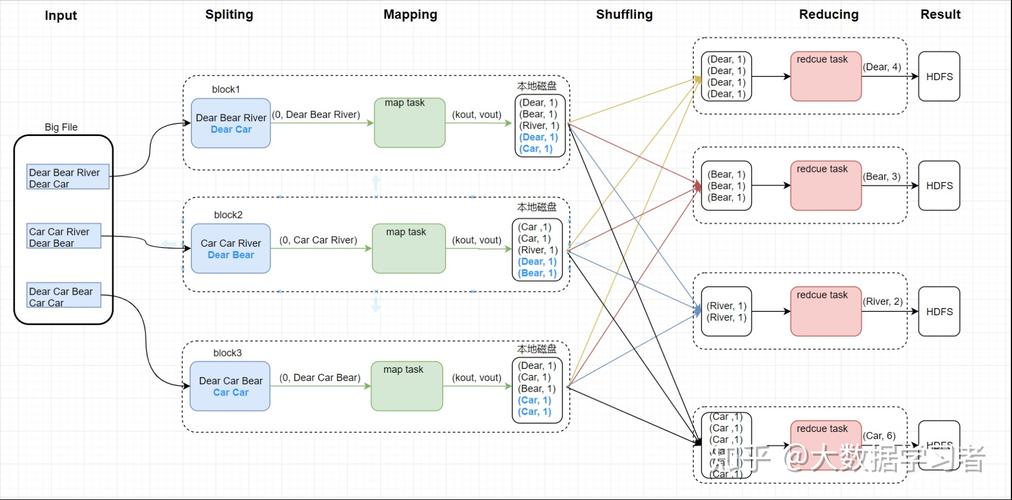
1、MapReduce流程顺序
数据读取与输入格式
数据分片与Map任务生成
Map函数处理与中间数据生成
Shuffle阶段数据重新组织
Reduce阶段数据处理与输出
(图片来源网络,侵删)
2、Join顺序的Hint
Join顺序对查询性能影响
Hint语法格式与功能
自动调整与手动指定Join顺序
优化Join顺序提升查询性能
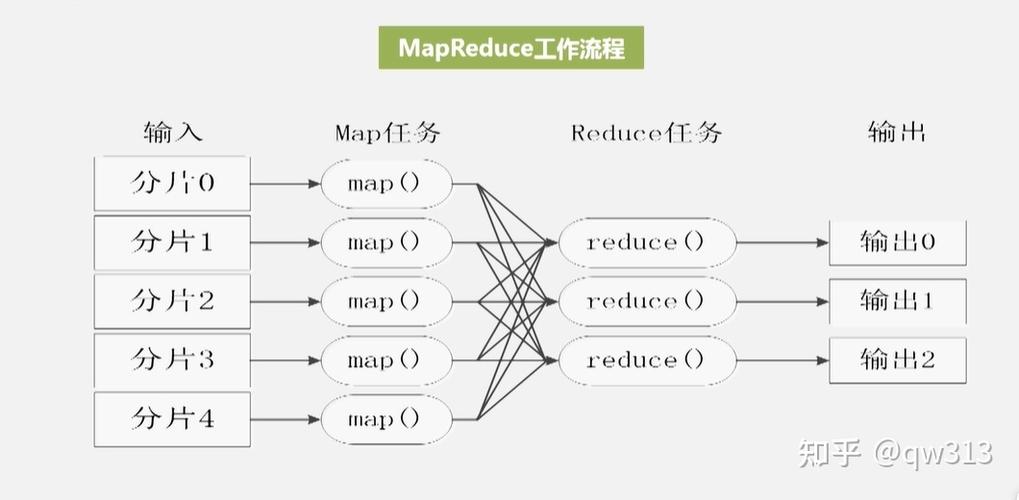
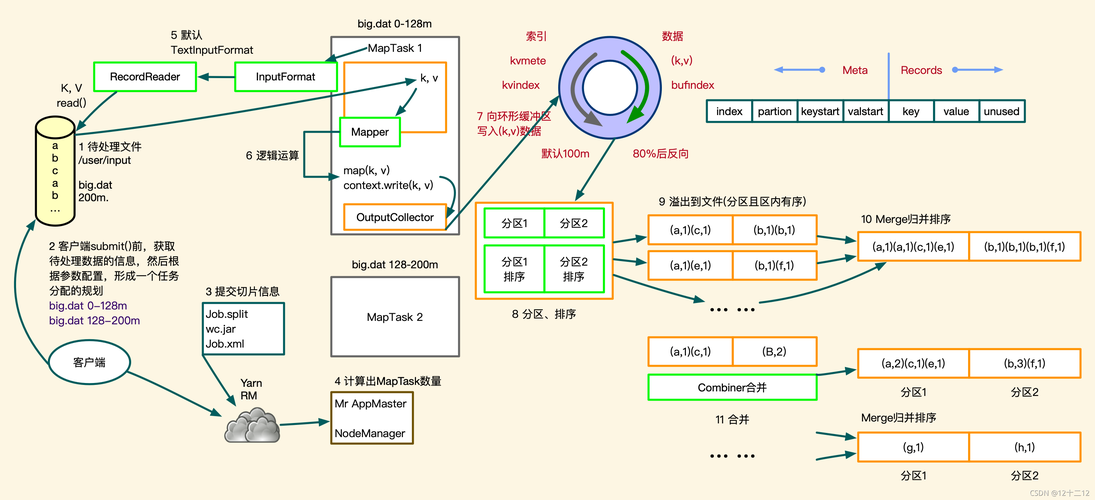
3、MapReduce流程详解
数据读取:从HDFS中读取文件
(图片来源网络,侵删)
数据分片:将数据切分成小的Split
Mapper:每一个Split生成一个MapTask
Shuffle:将每个MapTask中处理好的数据,重新排序后,进行分区
Reduce:将缓存中的数据进行进一步的排序和merge,形成一份文件
4、Join顺序的Hint实施指南
语法格式解析
指定表的Join顺序
优化Nested Loop Join使用
控制执行计划以提升性能
5、性能调优与问题诊断
监控MapReduce作业状态
识别并解决性能瓶颈
利用Hint进行查询优化
分析执行计划确定优化策略
6、扩展性与高阶应用
处理大规模数据集策略
实现复杂查询优化
结合数据本地化特性
应用其他高级Hint技巧
7、归纳与最佳实践
回顾MapReduce关键步骤
概括Join顺序Hint要点
推荐日常使用中的注意事项
分享成功案例与经验教训
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/831387.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复