


MapReduce运行参数是用于配置和优化MapReduce作业性能的关键设置。这些参数包括输入输出格式、资源分配、并行度设定等,正确配置可以显著提高作业执行效率和系统资源的利用率。
MapReduce 运行参数和配置参数主要包括以下几类:

(图片来源网络,侵删)
1、作业级别参数
2、任务级别参数
3、MapReduce 框架参数
4、Hadoop 通用参数
下面分别对这四类参数进行详细解释:
1. 作业级别参数
作业级别参数是在提交 MapReduce 作业时设置的,主要用于控制整个作业的运行,以下是一些常用的作业级别参数:
(图片来源网络,侵删)
| 参数名 | 描述 |
mapreduce.job.reduces | 设置作业中 reduce 任务的数量 |
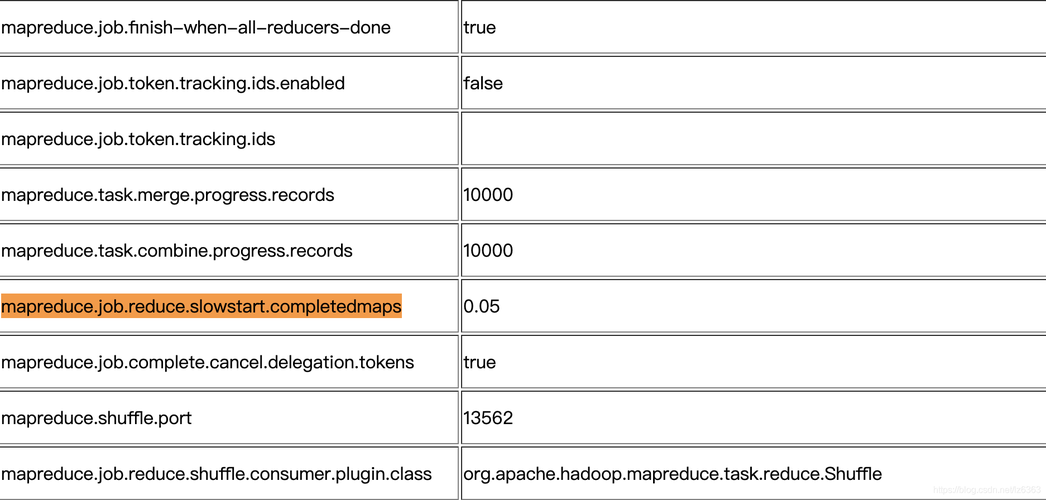
mapreduce.job.reduce.slowstart.completed.maps | 设置 reduce 任务开始复制数据的 map 任务完成比例 |
mapreduce.job.reduce.slowstart.completed.maps | 设置 reduce 任务开始复制数据的 map 任务完成比例 |
mapreduce.input.fileinputformat.split.maxsize | 设置输入分片的最大大小 |
mapreduce.input.fileinputformat.split.minsize | 设置输入分片的最小大小 |
mapreduce.output.fileoutputformat.compress | 设置输出文件是否压缩 |
mapreduce.output.fileoutputformat.compress.codec | 设置输出文件压缩使用的编码器 |
mapreduce.output.fileoutputformat.compress.type | 设置输出文件压缩类型(RECORD/BLOCK) |
mapreduce.output.fileoutputformat.sort.before.write | 设置在写入输出文件前是否进行排序 |
2. 任务级别参数
任务级别参数是在 MapReduce 任务运行时设置的,主要用于控制单个任务的运行,以下是一些常用的任务级别参数:
| 参数名 | 描述 |
mapreduce.map.memory.mb | 设置每个 map 任务的内存限制 |
mapreduce.reduce.memory.mb | 设置每个 reduce 任务的内存限制 |
mapreduce.map.java.opts | 设置 map 任务的 Java 虚拟机参数 |
mapreduce.reduce.java.opts | 设置 reduce 任务的 Java 虚拟机参数 |
mapreduce.task.timeout | 设置任务超时时间 |
mapreduce.tasktracker.http.threads | 设置 TaskTracker 的 HTTP 线程数 |
mapreduce.tasktracker.map.tasks.maximum | 设置 TaskTracker 上同时运行的 map 任务数上限 |
mapreduce.tasktracker.reduce.tasks.maximum | 设置 TaskTracker 上同时运行的 reduce 任务数上限 |
3. MapReduce 框架参数
MapReduce 框架参数主要用于控制 MapReduce 框架的运行,以下是一些常用的 MapReduce 框架参数:
| 参数名 | 描述 |
yarn.nodemanager.auxservices | 设置 NodeManager 上的辅助服务 |
yarn.nodemanager.pmemcheckenabled | 设置是否启用物理内存检查 |
yarn.nodemanager.vmemcheckenabled | 设置是否启用虚拟内存检查 |
yarn.nodemanager.resource.memorymb | 设置 NodeManager 可用内存总量 |
yarn.nodemanager.resource.cpuvcores | 设置 NodeManager 可用 CPU 核心数 |
yarn.nodemanager.localdirs | 设置 NodeManager 的数据存储目录 |
yarn.nodemanager.logdirs | 设置 NodeManager 的日志目录 |
yarn.nodemanager.delete.debugdelaysec | 设置删除调试文件的延迟时间 |
4. Hadoop 通用参数
Hadoop 通用参数适用于 Hadoop 集群的所有组件,以下是一些常用的 Hadoop 通用参数:
| 参数名 | 描述 |
fs.defaultFS | 设置默认的文件系统URI |
io.file.buffer.size | 设置文件系统 I/O 缓冲区大小 |
io.sort.factor | 设置外部排序的溢出文件数量 |
io.sort.record.percent | 设置外部排序过程中触发合并的记录百分比 |
io.sort.spill.percent | 设置外部排序过程中触发写磁盘的缓冲区百分比 |
io.sort.mb | 设置排序操作的内存缓冲区大小 |
mapreduce.jobhistory.address | 设置 JobHistoryServer 的地址 |
mapreduce.jobhistory.webapp.address | 设置 JobHistory UI 的地址 |
mapreduce.jobhistory.intermediatedonedir | 设置 JobHistory 中间结果的存储目录 |
mapreduce.jobhistory.donedir | 设置 JobHistory 最终结果的存储目录 |
这些参数可以通过配置文件(如mapredsite.xml、yarnsite.xml、hadoopenv.sh 等)或在提交作业时通过命令行参数进行设置。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/830950.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复